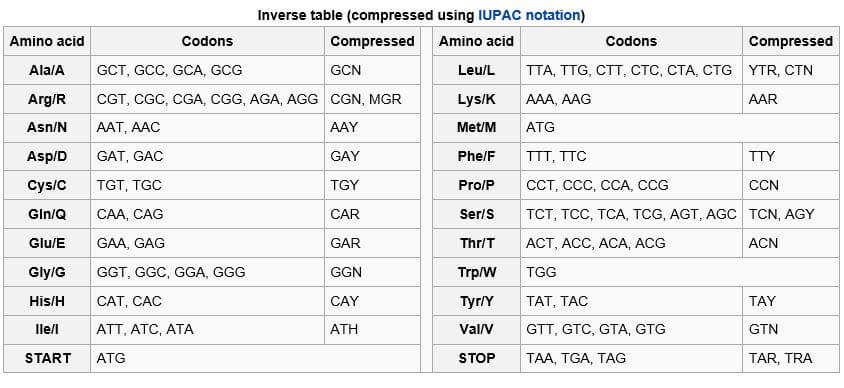
I posted a long answer on Quora.com where it sort of didn’t do well.
Answers given by others were much shorter but they seemed, at least to me, to lack geometric insights. After two days my answer was ranked as the most read, but for some reason no one upvoted it. It did receive a few positive replies though.
I can’t help but believe that there must be nerds in cyberspace who might enjoy my answer. Why not post it on my blog? Maybe someday one of my grandkids will get interested in math and read it.
Who knows?
Anyway, below is a pic and a working GIF, which should help folks understand better. Anyone who doesn’t understand something can always click on a link for more information.
Here is the drawing I added and the answer:
This diagram is excellent but contains a mystery point not on the unit circle — . The point is shown at .2078… on the real number line. An imaginary number raised to the power of an imaginary number yields a result that is a real number. How can that be? It’s something to ponder; something to think about. The Editorial Board
What is ?
The expression evaluates to minus one; the answer is (-1). Why?
Numbers like these are called complex numbers. They are two-dimensional numbers that can be drawn on graph-paper instead of on a one-dimensional number line, like the counting numbers. They are used to analyze wave functions — i.e. phenomenon that are repetitive — like alternating current in the field of electrical engineering, for example.
A simplified explanation of starts at 02:30.
“e” is a number that cannot be written as a fraction (or a ratio of whole numbers). It is an irrational number (like π, for instance). It can be approximated by adding up an arbitrary number of terms in a certain infinite series to reach whatever level of precision one wants. To work with “e” in practical problems, it must be rounded off to some convenient number of decimal places.
Punch “e” into a calculator and it returns the value 2.7182…. The beauty of working with “e” is that derivatives and integrals of functions based on exponential powers of “e” are easy to calculate. Both the integral and the derivative of ex is ex — a happy circumstance that makes the number “e” unusually curious and extraordinarily useful in every discipline where calculus is necessary for analysis.
What is “e” raised to the power of (-iπ) ?
A wonderful feature of the mathematics of complex numbers is that all the values of expressions that involve the number “e” raised to the power of “i” times anything lie on the edge (or perimeter) of a circle of radius 1. This feature makes understanding the expressions easy.
I should mention that any point in the complex plane can be reached by adding a number in front of to stretch or shrink the unit circle of values. We aren’t going to go there. In this essay “e” is always preceded by the number “one“, which by convention is never shown.
The number next to the letter “i” is simply the angle in radians where the answer lies on the circle. What is a radian? It’s the radius of the circle, of course, which in a unit circle is always “one”, right?
Wrap that distance around the circle starting at the right and working counter-clockwise to the left. Draw a line from the center of the circle at the angle (the number of radius pieces) specified in the exponent of “e” and it will intersect the circle at the value of the expression. What could be easier?
For the particular question we are struggling to answer, the number in the exponent next to “i” is (-π), correct?
“π radians” is 3.14159… radius pieces — or 180° — right? The minus sign is simply a direction indicator that in this case tells us to move clockwise around the unit circle — instead of counter-clockwise were the sign positive.
After drawing a unit circle on graph paper, place your pencil at (1 + 0i)—located at zero radians (or zero degrees) — and trace 180° clockwise around the circle. Remember that the circle’s radius is one and its center is located at zero, which in two dimensional, complex space is (0 + 0i). You will end up at the value (-1 + 0i) on the opposite side of the circle, which is the answer, by the way.
[Trace the diagram several paragraphs above with your finger if you don’t have graph paper and a pencil. No worries.]
Notice that +π radians takes you to the same place as -π radians, right? Counter clockwise or clockwise, the value you will land on is (-1 + 0i), which is -1. The answer is minus one.
Imagine that the number next to “i” is (π/2) radians (1.57… radius pieces). That’s 90°, agreed? The sign is positive, so trace the circle 90° counter-clockwise. You end at (0 + i), which is straight up. “i” in this case is a distance of one unit upward from the horizontal number line, so write the number as (0 + i) — zero distance in the horizontal direction and “plus one” distance in the “i” (or vertical) direction.
So, the “i” in the exponent of “e” says to “look here” to find the angle where the value of the answer lies on the unit circle; on the other hand, the “i” in the rectangular coordinates of a two-dimensional number like (0 + i) says “look here” to find the vertical distance above or below the horizontal number line.
When evaluating “e” raised to the power of “i” times anything, the angle next to “i”—call it “θ”—can be transformed into rectangular coordinates by using this expression: [cos(θ) + i sin(θ)].
For example: say that the exponent of “e” is i(π/3). (π/3) radians (1.047… radius pieces) wraps around the circumference to 60°, right? The cosine of 60° is 0.5 and the sine of 60° is .866….
So the value of “e” raised to the power of i(π/3) is by substitution (0.5 + .866… i ). It is a two-dimensional number. And it lies on the unit circle.
The bigger the exponent on “e” the more times someone will have to trace around the circle to land at the answer. But they never leave the circle. The result is always found on the circle between 0 and 2π radians (or 0° and 360°) no matter how large the exponent.
It’s why these expressions involving “e” and “i” are ideal for working with repetitive, sinusoidal (wave-like) phenomenon.
In this essay Billy Lee uses θ in place of the Greek letter φ shown in this GIF. Remember that ”r” equals ”one” in a unit circle, so it’s typically not shown. The Editorial Board
In case some readers are still wondering about what radians are, let’s review:
A radian is the radius of a circle, which can be lifted and bent to fit perfectly on the edge of the circle. It takes a little more than three radius pieces (3.14159… to be more precise) to wrap from zero degrees to half-way around any circle of any size. This number — 3.14159… — is the number called “π”. 2π radians are a little bit more than six-and-a-quarter radians (radius pieces), which will completely span the perimeter (or circumference) of a circle.
A radian is about 57.3° of arc. Multiply 3.1416 by 57.3° to see how close to 180° it is. I get 180.01… . The result is really close to 180° considering that both numbers are irrational and rounded off to only a few decimal places.
One of the rules of working with complex numbers is this: multiplying any number by “i” rotates that number by 90°. The number “i” is always located at 90° on the unit circle by definition, right? By the rule, multiplying “i” by “i” rotates it another 90° counter-clockwise, which moves it to 180° on the circle.
180° on the unit circle is the point (-1 + 0i), which is minus one, right?
So yes, absolutely, “i” times “i” is equal to -1. It follows that the square root of minus one must be “i”. Thought of in this way, the square root of a minus one isn’t mysterious.
It is helpful to think of complex numbers as two dimensional numbers with real and imaginary components. There is nothing imaginary, though, about the vertical component of a two-dimensional number.
The people who came up with these numbers thought they were imagining things. The idea that two-dimensional numbers can exist on a plane was too radical at the time for anyone to believe. Numbers, they believed, only existed on a one-dimensional number line of one dimension and no place else.
Of course they were mistaken. Numbers can live in two, three, or even more dimensions. They can be as multi-dimensional as needed to solve whatever the mysteries of mathematical analysis might require.
Everyone wants to live as long as possible, right? Well, maybe not everyone.
Someone confided in me that their nightmare was they wouldn’t die; they would never get respite from an existence that terrified them, that depressed them, that hurt them, that disappointed and discouraged them; that humiliated them; that abused them; that made them wish they were never born.
Another friend confessed that she wished she had never been born because she was afraid to die. The certainty of death made living not worth the trouble. Anxiety about the end of life robbed her of joy. She found that she was unable to kick back and relax, because dark angels circled just outside her field of vision; one day, she was certain, the angels were going to pounce. The end would be brutal.
I remember hearing a story about a young mother who lay dying while her family knelt at her bedside. A scene of sweet-sorrow unfolded as the woman struggled to breathe in the presence of loved-ones. A worried husband, anxious toddlers, her parents, and a few close friends sang hymns to reassure and cast comfort. They clung to one another united by the belief that God would carry momma gently to heaven in his caring arms.
Momma didn’t experience death that way. She bolted up, away from her pillow. She stared wild-eyed at something behind her visitors; something no one saw.
She screamed. No!No! No!
Momma dropped off the bed, slammed to the floor, and rolled onto her back making a loud crack — like a toppled refrigerator. She stared at the ceiling, face frozen, eyes open; crazed, except that now she was dead and too heavy for anyone to move.
Steve McQueen died at age 50 from cardiac arrest at a cancer treatment facility in Mexico in 1980. He made thirty movies; many were blockbusters.
Some people love life and don’t want to leave. I remember Steve McQueen, an actor from yesteryear who had everything to live for. He was a happy race-car enthusiast, a leading man in movies, incredibly handsome, kind, and grateful for every blessing his wonderful life showered on him.
He got cancer. Stateside doctors told him he had no chance. Death was certain. He traveled to Mexico to seek out a cancer recovery center he learned about from friends.
I remember hearing him weep during a radio interview because, he said, the medical director had saved his life. He thanked him again and again. He couldn’t say it enough. I felt touched. He loved life; his gratitude seemed to resonate with the voices of the angels. I would have gladly traded places with him.
Two days later, the newspapers and television news shows reported that he died. What went through his mind when he finally realized that his life wasn’t going to turn out the way he planned?
For people who seek death, death is easy to find — if they have the courage to face what comes after; if the pain of living exceeds the risks of non-existence or the risks of being reborn as someone new or the possibility of falling into the pits of Hell or wherever they imagine might lie the alternative to the pain of life on Earth. Relief is as close as the closeted gun, the nearest bridge, the bottle of medicine in the bathroom cabinet.
I feel bad for people who have been ruined, I do. Far more people kill themselves than are killed by others. No one believes it, but it’s true.
I don’t want to dwell on the ruined, because another class of people — a smaller group, I sometimes wonder — want to live.
The man shown in this pic (from 2011) was active and working at age 106. He and hundreds like him have been the subject of scientific studies about human longevity. They are kind and gentle people who enjoy life by all accounts; they wish only to live as long as possible.
These are the folks who never suffer from depression; experience a major illness; spend time in hospital or prison; lose a child or spouse; worry about the sparkle of a crooked tooth or the part on their head of radiant hair. They don’t worry about any lack of symmetry that might render them unattractive — or about getting their way in life, because they always do.
I want to talk about the powerful, beautiful, effective people who everyone seems to want to be. I want to talk about the happy people like Steve McQueen who will always chase a fantasy, because they want to live in the worst, most desperate way.
I want to talk about the people who freeze themselves in the hope that in a benevolent future they will be thawed, and life will continue; I want to talk about the people who take 150 pills a day to prevent every ailment and strengthen every sinew.
I want to talk about the brilliant, optimistic people who expect that if they can just figure things out the right way, life awaits them for as long as they want it. It’s all up to them. They will find a way to make life last; to achieve an eternal success, because they always have.
Is it time for a reality check?
Is this a good time to reveal some truths? — shocking truths, perhaps, for a few readers? I want to predict our futures — all of our futures — as separate individuals with private lives; and as a species — a species anthropologists describe by the Latin words, homo sapiens, (smart people), which they use among themselves to differentiate you and me from all the other groups of living things we rarely notice or even think about.
Let’s smarten up for a few moments and defend our reputation among the kingdoms of the animals and the plants. Let’s think about best case scenarios for survival and whether we can make our dreams come true.
One statistic to keep in mind that is easily verified (and it might startle some readers): two-thirds of all deaths are not caused by aging.
So let’s move on.
Who wants to start with species survival? Who would rather address the riddle about how to lengthen an individual life?
Ok, the responses I think I hear in my head are nearly unanimous. People want to know how they themselves can live longer, correct? People want to know how long they will live when everything is set right.
So, why not start with a best case scenario for individuals? I promise to address the issues of survival for homo sapiens later, after a few paragraphs more.
Here are some simple, best-case-scenario assumptions:
Assume that disease is eradicated. We reach a state under the protections of ObamaCare (or maybe Trump-Care, who knows?) where no one dies in hospital anymore; all diseases have cures and can be prevented; in fact, disease is eliminated from the face of the earth — no bacterial or viral infections; no malevolent genes gone haywire; no Alzheimer’s or mental impairments; no more skin rashes or herpes or warts or annoying ear-wax that morphs into septic brain infections.
Disease is gone. Now take another step. Make a leap of faith. Assume that the genetics of aging is solved and that no one grows old. No one deteriorates. Skin does not wrinkle; no more age spots or rotting teeth; loss of hair and muscle-mass becomes a thing of the past. Aches and pains and constipation and diarrhea and acid reflux — what be them? They gone!
Our long medical nightmare is over, to paraphrase the words of President Gerald Ford on the night he pardoned Dick Nixon so that no prosecutor could ever charge and convict him for being a crook and throwing an election.
OK. What now become the odds for our survival? How long can one person expect to live? I think everyone can see, there’s something we didn’t consider; one thing no one thought of; a missing piece in the puzzle of living-large that is going to leap up and grab each of us sooner or later — unless we live bundled by bubble-wrap in a bunker, miles below the surface of the earth. We all know what it is, right?
It happens when we bike on a country road, and a candy-coking cell-talker in a Corvette runs us over. It happens when we climb Mount Everest (just to cross it off our bucket-list) and whoops! someone in the group forgot to tie their shoelaces. People see a video on the evening news — dead people buried in snow.
It happens when flying an airplane — a flock of geese smashes the windscreen. The pilot gets sucked out the opening — shredded by shards of glass.
We visit an amusement park to thrill ourselves on a ride that throws us upside down and — oops again! — an unscheduled stop; a mechanical malfunction. Two hours later, rescued, we’re vegetables. Homo sapiens don’t do well hanging upside down for long periods.
Yes, the one thing no one counted on is accidents.
Accidents kill a lot of people every single day. And nothing is going to change that fact unless people decide to live in virtual reality and never get off the couch to go outdoors or walk their dog.
Well, every year one person in a thousand dies in a screw-up by somebody, usually themselves. It doesn’t sound like much, but for the person who dies it’s one death too many. Anyone who expects to live 25,000 years should perform a statistical analysis to see what the chances are they will live that long.
Why guess?
The way the math works is this: figure the chances of living deadly-accident-free for one year (it’s 999/1000), then multiply this number by itself for each year of life.
Save time by using the exponent key on a calculator to enter years, anyone who doesn’t want to spend a week multiplying the same number over and over 25,000 times. The result will give the chances for survival over a span of that many years. Try some other numbers to make comparisons.
The bottom line is this: no one has any realistic hope at all of living more than 10,000 years or so. Of the seven billion humans alive today, only one in 22,000 can expect to live to the age 10,000.
A mere 2,000 people out of 7,000,000,000 will survive to see year 15,000. There’s a small chance (one in ten) that a solitary person might make it to 25,000 years, but they will be an outlier; a statistical anomaly. Who wants to be an anomaly? Not me.
In most cases; under the most realistic scenarios, the chances are that everyone alive today is going to be dead at age 25,000 because of accidents alone. They will die healthy though. It might be consolation for some.
No one will make it to year 25,000. That’s my bet. It’s not going to happen 90% of the time.
Accidents happen.
OK. Now that everybody knows that our individual situation is hopeless, what about the survival of our species — the human race (for those who disdain the scientific term, homo sapiens)?
Not sure why this video, but it’s pretty good, so let’s go with it.
I am sorry to report that the survival odds for our species are actually far worse than the odds for our survival as individuals. This depressing fact means that we can totally ignore the individual survival scenario we just took so much effort to describe. If our species dies-off early, individuals are going to die early too.
How can this terrible situation be possible? It seems so unfair.
I’ve been reading the book Global Catastrophic Risks — a collection of essays edited by Nick Bostrom and Milan M. Cirkovic — first published nine years ago (in 2008) when species survival was more certain than it is now. These brilliant men collected essays written by other forward-thinking geniuses who describe in delirious detail thirteen (or so) existential threats to the survival of humans. Some readers might want to review the list.
The authors argue that certain scenarios involving these threats will create an inevitable cascade of events that lead to the melt-down of civilization and a kill-strike against the human-species. I decided to assign a 1 in 10,000 chance of occurrence to each of these 13 catastrophes and crunch the numbers to understand how much danger people on Earth might be facing.
What I discovered scared me.
A super-volcano eruption in Toba, Indonesia 70,000 years ago reduced the population of humans on Earth to less than 4,000. Volcanoes that we know about today, like the one under Yellowstone National Park, might be larger and more dangerous.
For one thing, it’s not possible to know if 1 in 10,000 is an optimistic or pessimistic assessment of each of these risks. Nuclear war might be 1 in 100; climate change — 1 in 50; asteroids — 1 in 50,000; supernovae — 1 in 100,000,000; artificial intelligence — 1 in 10.
Who knows?
Can humans survive 10,000 years without a pandemic or nuclear war? No one knows.
Experts resort to heuristics, which erupt from biases even they don’t know they carry. I suppose a gut-check by an expert has more validity than a seat-of-the-pants guess by a pontificator. I will give you that. But the irony is that no matter who is right, no one will know because we are all going to die.
Evidence in the fossil and genetic record already shows that at least three human-like species are known to have come and gone during the past several 100,000 years or so, including Neanderthals and Denisovans. Extinction of intelligent, human-like species happens more often than not — 3 out of 4 times, maybe more if scientists continue to dig and look.
Number-crunching shows that if my 1 in 10,000 or soyears risk assessments are anywhere close to being realistic, humans have no more than a 1 in 4 chance to avoid extinction during the next 1,000 years. Our chance to survive approaches zero as the number of years reaches into the realm of 5,000 years and beyond.
Humans have recorded their stories for 5,000 years. Some call these stories, history. Sometime during the next 5,000 years, history will end unless humans lower the odds of these catastrophes to much less than 1 in 10,000.
We are truly stupid — dumber than earthworms — to refuse to make the effort to increase our survival prospects by lowering these probabilities, these ratios, to one-in-one-hundred-thousand or better still, one-in-a-million or even better, one-in-one-hundred million. Why not one-in-a-gazillion?
How? It’s the big question.
Reducing odds of catastrophe is the most important thing. It’s urgent. Failure seals our fate.
We search the heavens. No one seems to be broadcasting from out there. Maybe it’s something simple like Miyake events, which some argue make communication infrastructure near stars impossible to sustain.
What science hears is silence… and tiny chirps, yes, but not from crickets.
I have a lot to say about renormalization; if I wait until I’ve read everything I need to know about it, my essay will never be written; I’ll die first; there isn’t enough time.
Click this link and the one above to read what some experts argue is the why and how of renormalization. Do it after reading my essay, though.
Our guess is that this graphic will be incomprehensible to the typical reader of Billy Lee’s blog. So, don’t worry about it. Billy Lee isn’t going to explain it, anyway. More important things need to be told that everyone can understand, and they will. The Editorial Board
There’s a problem inside the science of science; there always has been. Facts don’t match the mathematics of theories people invent to explain them. Math seems to remove important ambiguities that underlie all reality.
People noticed the problem as soon as they started doing science. The diameter of a circle and its circumference was never certain; not when Pythagoras studied it 2,500 years ago or now; the number π is the problem; it’s irrational, not a fraction; it’s a number with no end and no pattern — 3.14159…forever into infinity.
More confounding, π is a number which transcends all attempts by algebra to compute it. It is a transcendental number that lies on the crossroads of mathematics and physical reality — a mysterious number at the heart of creation because without it the diameters, surface areas, and volumes of spheres could not be calculated with arbitrary precision.
For a circle, either the circumference or the diameter can be rational (written as a fraction) but not both. Perfect circles and spheres cannot exist in nature. Why? ”π” is irrational. It can’t be written like a fraction — a ratio — where one integer divides another.
The diameter of a circle must be multiplied by π to calculate its circumference; and vice-versa. No one can ever know everything about a circle because the number π is uncertain, undecidable, and in truth unknowable.
Long ago people learned to use the fraction 22 /7or, for more accuracy, 355/113. These fractions gave the wrong value for π but they were easy to work with and close enough to do engineering problems.
Fast forward to Isaac Newton, the English astronomer and mathematician, who studied the motion of the planets. Newton published Philosophiæ Naturalis Principia Mathematica in 1687. I have a modern copy in my library. It’s filled with formulas and derivations. Not one of them works to explain the real world — not one.
Newton’s equation for gravity describes the interaction between two objects — the strength of attraction between Sun and Earth, for example, and the resulting motion of Earth. The problem is the Moon and Mars and Venus, and many other bodies, warp the space-time waters in the pool where Earth and Sun swim. No way exists to write a formula to determine the future of such a system.
This simple three-body problem cannot be solved using a single equation. It’s not so simple. More than three bodies makes systems like these much harder to work with.
In 1887 Henri Poincare and Heinrich Bruns proved that such formulas cannot be written. The three-body problem (or any N-body problem, for that matter) cannot be solved by a single equation. Fudge-factors must be introduced by hand, Richard Feynman once complained. Powerful computers combined with numerical methods seem to work well enough for some problems.
Perturbation theory was proposed and developed. It helped a lot. Space exploration depends on it. It’s not perfect, though. Sometimes another fudge factor called rectification is needed to update changes as a system evolves. When NASA lands probes on Mars, no one knows exactly where the crafts are located on its surface relative to any reference point on the Earth.
Science uses perturbation methods in quantum mechanics and astronomy to describe the motions of both the very small and the very large. A general method of perturbations can be described in mathematics.
Even when using the signals from constellations of six or more Global Positioning Systems (GPS) deployed in high earth-orbit by various countries, it’s not possible to know exactly where anything is. Beet farmers out west combine the GPS systems of at least two countries to hone the courses of their tractors and plows.
On a good day farmers can locate a row of beets to within an eighth of an inch. That’s plenty good, but the several GPS systems they depend on are fragile and cost billions per year. In beet farming, an eighth inch isn’t perfect, but it’s close enough.
Quantum physics is another frontier of knowledge that presents roadblocks to precision. Physicists have invented more excuses for why they can’t get anything exactly right than probably any other group of scientists. Quantum physics is about a hundred years old, but today the problems seem more insurmountable than ever.
The sub-atomic world seems to be smeared and messy. Vast numbers of particles — virtual and actual — makes the use of mathematics problematic. This pic is an artist’s conception. Concepts such as ”looks like” have no meaning at sub-atomic scales, because small things can’t be resolved by any frequency of light that enables them to be visualized realistically by humans.
Insurmountable?
Why?
Well, the interaction of sub-atomic particles with themselves combined with, I don’t know, their interactions with swarms of virtual particles might disrupt the expected correlations between theories and experimental results. The mismatches can be spectacular. They sometimes dwarf the N-body problems of astronomy.
Worse — there is the problem of scales. For one thing, electrical forces are a billion times a billion times a billion times a billion times stronger than gravitational forces at sub-atomic scales. Forces appear to manifest themselves according to the distances across which they interact. It’s odd.
Measuring the charge on electrons produces different results depending on their energy. High energy electrons interact strongly; low energy electrons, not so much. So again, how can experimental results lead to theories that are both accurate and predictive? Divergent amplitudes that lead to infinities aren’t helpful.
An infinity of scales pile up to produce troublesome infinities in the math, which tend to erode the predictive usefulness of formulas and diagrams. Once again, researchers are forced to fabricate fudge-factors. Renormalization is the buzzword for several popular methods.
Probably the best-known renormalization technique was described by Shinichiro Tomonaga in his 1965 Nobel Prize speech. According to the view of retired Harvard physicist Rodney Brooks, Tomonaga implied that …replacing the calculated values of mass and charge, infinite though they may be, with the experimental values… is the adjustment necessary to make things right, at least sometimes.
Isn’t such an approach akin to cheating? — at least to working theorists worth their salt? Well, maybe… but as far as I know results are all that matter. Truncation and faulty data mean that math can never match well with physical reality, anyway.
Folks who developed the theory of quantum electrodynamics (QED) used perturbation methods to bootstrap their ideas to useful explanations. Their work produced annoying infinities until they introduced creative renormalization techniques to chase them away.
At first physicists felt uncomfortable discarding the infinities that showed up in their equations; they hated introducing fudge-factors. Maybe they felt they were smearing theories with experimental results that weren’t necessarily accurate. Some may have thought that a poor match between math, theory, and experimental results meant something bad; they didn’t understand the hidden truth they struggled to lay bare.
Philosopher Robert Pirsig believed the number of possible explanations scientists could invent for phenomena were in fact unlimited. Despite all the math and convolutions of math, Pirsig believed something mysterious and intangible like quality or morality guided human understanding of the Cosmos. An infinity of notions he saw floating inside his mind drove him insane, at least in the years before he wrote his classic Zen and the Art of Motorcycle Maintenance.
The newest generation of scientists aren’t embarrassed by anomalies. They “shut up and calculate.” Digital somersaults executed to validate their work are impossible for average people to understand, much less perform. Researchers determine scales, introduce “cut-offs“, and extract the appropriate physics to make suitable matches of their math with experimental results. They put the horse before the cart more times than not, some observers might say.
Apologists say, no. Renormalization is simply a reshuffling of parameters in a theory to prevent its failure. Renormalization doesn’t sweep infinities under the rug; it is a set of techniques scientists use to make useful predictions in the face of divergences, infinities, and blowup of scales which might otherwise wreck progress in quantum physics, condensed matter physics, and even statistics. From YouTube video above.
It’s not always wise to question smart folks, but renormalization seems a bit desperate, at least to my way of thinking. Is there a better way?
The complexity of the language scientists use to understand and explain the world of the very small is a convincing clue that they could be missing pieces of puzzles, which might not be solvable by humans regardless how much IQ any petri-dish of gametes might deliver to brains of future scientists.
It’s possible that humans, who use language and mathematics to ponder and explain, are not properly hardwired to model complexities of the universe. Folks lack brainpower enough to create algorithms for ultimate understanding.
Perhaps Elon Musk’s Neuralink add-ons will help someday.
Nick Bostrom, author of SUPERINTELLIGENCE – Paths, Dangers, Strategies
The smartest thinkers — people like Nick Bostrom and Pedro Domingos (who wrote The Master Algorithm) — suggest artificial super-intelligence might be developed and hardwired with hundreds or thousands of levels — each loaded with trillions of parallel links — to digest all meta-data, books, videos, and internet information (a complete library of human knowledge) to train armies of computers to discover paths to knowledge unreachable by puny humanoid intelligence.
Super-intelligent computer systems might achieve understanding in days or weeks that all humans working together over millennia might never acquire. The risk of course is that such intelligence, when unleashed, might enslave us all.
Another downside might involve communication between humans and machines. Think of a father — a math professor — teaching calculus to the family cat. It’s hopeless, right?
Imagine an expert in AI & quantum computation joining forces with billionaire Musk who possesses the rocket launching power of a country. Right now, neither is getting along, Elon said. They don’t speak. It could be a good thing, right?
What are the consequences?
Entrepreneurs don’t like to be regulated. Temptations unleashed by unregulated military power and AI attained science secrets falling into the hands of two men — nice men like Elon and Larry appear to be — might push humanity in time to unmitigated… what’s the word I’m looking for?
I heard Elon say he doesn’t like regulation, but he wants to be regulated. He believes super-intelligence will be civilization ending. He’s planning to put a colony on Mars to escape its power and ensure human survival.
Elon Musk
Is Elon saying he doesn’t trust himself, that he doesn’t trust people he knows like Larry? Are these guys demanding governments save Earth from themselves?
I haven’t heard Larry ask for anything like that. He keeps a low profile. God bless him as he collects everything everyone says and does in cyber-space.
Think about it.
Think about what it means.
We have maybe ten years, tops; maybe less. Maybe it’s ten days. Maybe the worst has already happened, but no one said anything. Somebody, think of something — fast.
Who imagined that laissez-faire capitalism might someday spawn an airtight autocracy that enslaves the world?
Humans are wise to renormalize their aspirations — their civilizations — before infinities of misery wreck Earth and freeless futures emerge that no one wants.
Many smart physicists wonder about it; some obsess over it; a few have gone mad. Physicists like the late Richard Feynman said that it’s not something any human can or will ever understand; it’s a rabbit-hole that quantum physicists must stand beside and peer into to do their work; but for heaven’s sake don’t rappel into its depths. No one who does has ever returned and talked sense about it.
I’m a Pontificator, not a scientist. I hope I don’t start to regret writing this essay. I hope I don’t make an ass of myself as I dare to go where angels fear to tread.
My plan is to explain a mystery of existence that can’t be explained — even to people who have math skills, which I am certain most of my readers don’t. Lack of skills should not trouble anyone, because if anyone has them, they won’t understand my explanation anyway.
My destiny is failure. I don’t care. My promise, as always, is accuracy. If people point out errors, I fix them. I write to understand; to discover and learn.
My recommendation to readers is to take a dose of whatever medicine calms their nerves; to swallow whatever stimulant might ignite electrical fires in their brains; to inhale, if necessary, doctor-prescribed drugs to amplify conscious experience and broaden their view of the cosmos. Take a trip with me; let me guide you. When we’re done, you will know nothing about the fine-structure constant except its value and a few ways curious people think about it.
Oh yes, we’re going to rappel into the depths of the rabbit-hole, I most certainly assure you, but we’ll descend into the abyss together. When we get lost (and we most certainly will) — should we fall into despair and abandon our will to fight our way back — we’ll have a good laugh; we’ll cry; we’ll fall to our knees; we’ll become hysterics; we’ll roll on the soft grass we can feel but not see; we will weep the loud belly-laugh sobs of the hopelessly confused and completely insane — always together, whenever necessary.
We will get lost together. This rabbit-hole is the Krubera Cave of Abkhazia land. It is the deepest cave in the world. Notice the tiny humans, for scale.
Isn’t getting lost with a friend what makes life worth living? Everyone gets lost eventually; it’s better when we get lost together. Getting lost with someone who doesn’t give a care; who won’t even pretend to understand the simplest things about the deep, dark places that lie miles beyond our grasp; that lie beneath our feet; that lie, in some cases, just behind our eyeballs; it’s what living large is all about.
Isn’t it?
Well, for those who fear getting lost, what follows is a map to important rooms in the rather elaborate labyrinth of this essay. Click on subheadings to wander about in the caverns of knowledge wherever you will. Don’t blame me if you miss amazing stuff. Amazing is what hides within and between the rooms for anyone to discover who has the serenity to take their time, follow the spelunking Sherpa (me), and trust that he (me) will extricate them eventually — sane and unharmed.
Anyway, relax. Don’t be nervous. The fine-structure constant is simply a number — a pure number. It has no meaning. It stands for nothing — not inches or feet or speed or weight; not anything. What can be more harmless than a number that has no meaning?
Well, most physicists think it reveals, somehow, something fundamental and complicated going on in the inner workings of atoms — dynamics that will never be observed or confirmed, because they can’t be. The world inside an atom is impossibly small; no advance in technology will ever open that world to direct observation by humans.
What physicists can observe is the frequencies of light that enormous collections of atoms emit. They use prisms and spectrographs. What they see is structure in the light where none should be. They see gaps — very small gaps inside a single band of color, for example. They call it fine structure.
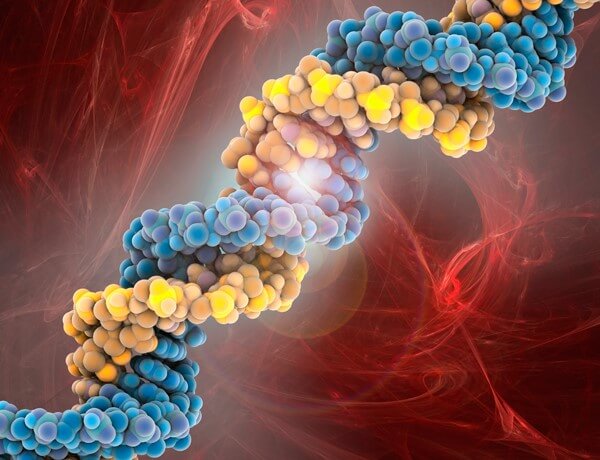
The Greek letter alpha (α) is the shortcut folks use for the fine-structure constant, so they don’t have to say a lot of words. The number is the square of another number that can have (and almost always does have) two or more parts — a complex number. Complex numbers have real and imaginary parts; math people say that complex numbers are usually two dimensional; they must be drawn on a sheet of two dimensional graph paper — not on a number line, like counting numbers always are.
Don’t let me turn this essay into a math lesson; please, …no. We can’t have readers projectile vomiting or rocking to the catatonic rhythms of a panic attack. We took our medicines, didn’t we? We’re going to be fine.
I beg readers to trust; to bear with me for a few sentences more. It will do no harm. It might do good. Besides, we can get through this, together.
Like me, you, dear reader, are going to experience power and euphoria, because when people summon courage; when they trust; when they lean on one another; when — like countless others — you put your full weight on me; I will carry you. You are about to experience truth, maybe for the first time in your life. Truth, the Ancient-of-Days once said, is that golden key that unlocks our prison of fears and sets us free.
Reality is going to change; minds will change; up is going to become down; first will become last and last first. Fear will turn into exhilaration; exhilaration into joy; joy into serenity; and serenity into power. But first, we must inner-tube our way down the foamy rapids of the next ten paragraphs. Thankfully, they are short paragraphs, yes….the journey is do-able, peeps. I will guide you.
The number (3 + 4i) is a complex number. It’s two dimensional. Pick a point in the middle of a piece of graph paper and call it zero (0 + 0i). Find a pencil — hopefully one with a sharp point. Move the point 3 spaces to the right of zero; then move it up 4 spaces. Make a mark. That mark is the number (3 + 4i). Mathematicians say that the “i” next to the “4” means “imaginary.” Don’t believe it.
They didn’t know what they were talking about, when first they worked out the protocols of two-dimensional numbers. The little “i” means “up and down.” That’s all. When the little “i” isn’t there, it means side to side. What could be more simple?
Draw a line from zero (0 + 0i) to the point (3 + 4i). The point is three squares to the right and 4 squares up. Put an arrow head on the point. The line is now an arrow, which is called a vector. This particular vector measures 5 squares long (get out a ruler and measure, anyone who doesn’t believe).
The vector (arrow) makes an angle of 53° from the horizontal. Find a protractor in your child’s pencil-box and measure it, anyone who doubts. So the number can be written as (5∠53), which simply means it is a vector that is five squares long and 53° counter-clockwise from horizontal. It is the same number as (3 + 4i), which is 3 squares over and 4 squares up.
The vectors used in quantum mechanics are smaller; they are less than one unit long, because physicists draw them to compute probabilities. A probability of one is 100%; it is certainty. Nothing is certain in quantum physics; the chances of anything at all are always less than certainty; always less than one; always less than 100%.
To multiply the vectors Z and W, add their angles and multiply their lengths. The vector ZW is the result; its overall length is called its amplitude. When both vectors Z and W are shorter than the side of one square in length, the vector ZW will become the shortest vector, not the longest (as it is in this example), because multiplying fractions together always results in a fraction that is less than the fractions that were multiplied. Right? To calculate what is called the probability density, simply multiply the length of the amplitude vector by itself, which will shrink it further, because its length (called its magnitude) is always a fraction that is less than one in quantum probability problems. This operation is called ‘’the Born Rule” where the magnitude of an amplitude is squared; it reduces a two-dimensional complex number to a one-dimensional unit-less number, which is — as said before — a probability. Experiments with electrons and photons must be performed to reveal interaction amplitude values; when these numbers are squared, the fine structure constant is the result. The probability density is a constant. That by itself is amazing.
Using simple rules, a vector that is less than one unit long can be used in the mathematics of quantum probabilities to shrink and rotate a second vector, which can shrink and rotate a third, and a fourth, and so on until the process of steps that make up a quantum event are completed. Lengths are multiplied; angles are added. The rules are that simple. The overall length of the resulting vector is called its amplitude.
Yes, other operations can be performed with complex numbers; with vectors. They have interesting properties. Multiplying and dividing by the “imaginary” i rotates vectors by 90°, for example. Click on links to learn more. Or visit the Khan Academy web-site to watch short videos. It’s not necessary to know how everything works to stumble through this article.
The likelihood that an electron will emit or absorb a photon cannot be derived from the mathematics of quantum mechanics. Neither can the force of the interaction. Both must be determined by experiment, which has revealed that the magnitude of these amplitudes is close to ten percent (.085424543… to be more exact), which is about eight-and-a-half percent.
What is surprising about this result is that when physicists multiply the amplitudes with themselves (that is, when they “square the amplitudes“) they get a one-dimensional number (called a probability density), which, in the case of photons and electrons, is equal to alpha (α), the fine-structure constant, which is .007297352… or 1 divided by 137.036… .
Get out the calculator and multiply .08524542 by itself, anyone who doesn’t believe. Divide the number “1” by 137.036 to confirm.
From the knowledge of the value of alpha (α) and other constants, the probabilities of the quantum world can be calculated; when combined with the knowledge of the vector angles, the position and momentum of electrons and photons, for example, can be described with magical accuracy — consistent with the well-known principle of uncertainty, of course, which readers can look up on Wikipedia, should they choose to get sidetracked, distracted, and hopelessly lost.
“Magical” is a good word, because these vectors aren’t real. They are made up — invented, really — designed to mimic mathematically the behavior of elementary particles studied by physicists in quantum experiments. No one knows why complex vector-math matches the experimental results so well, or even what the physical relationship of the vector-math might be (if any), which enables scientists to track and measure tiny bits of energy.
To be brutally honest, no one knows what the “tiny bits of energy” are, either. Tiny things like photons and electrons interact with measuring devices in the same ways the vector-math says they should. No one knows much more than that.
What is known is that the strong force of QCD is 137 times stronger than the electromagnetic force of QED — inside the center of atoms. Multiply the strong force by (α) to get the EM force. No one knows why.
There used to be hundreds of tiny little things that behaved inexplicably during experiments. It wasn’t only tiny pieces of electricity and light. Physicists started running out of names to call them all. They decided that the mess was too complicated; they discovered that they could simplify the chaos by inventing some new rules; by imagining new particles that, according to the new rules, might never be observed; they named them quarks.
By assigning crazy attributes (like color-coded strong forces) to these quarks, they found a way to reduce the number of elementary particles to seventeen; these are the stuff that makes up the so-called Standard Model. The model contains a collection of neutrons and muons; and quarks and gluons; and thirteen other things — researchers made the list of subatomic particles shorter and a lot easier to organize and think about.
Some particles are heavy, some are not; some are force carriers; one — the Higgs — imparts mass to the rest. The irony is this: none are particles; they only seem to be because of the way we look at and measure whatever they really are. And the math is simpler when we treat the ethereal mist like a collection of particles instead of tiny bundles of vibrating momentum within an infinite continuum of no one knows what.
Feynman diagrams help physicists think about what’s going on without getting bogged down in the mathematical details of subatomic particle interactions. View video below for more details. Diagram protocols start at 12:36 into the video.
Physicists have developed protocols to describe them all; to predict their behavior. One thing they want to know is how forcefully and in which direction these fundamental particles move when they interact, because collisions between subatomic particles can reveal clues about their nature; about their personalities, if anyone wants to think about them that way.
The force and direction of these collisions can be quantified by using complex (often three-dimensional) numbers to work out between particles a measure during experiments of their interaction probabilities and forces, which help theorists to derive numbers to balance their equations. These balancing numbers are called coupling constants.
The fine-structure constant is one of a few such coupling constants. It is used to make predictions about what will happen when electrons and photons interact, among other things. Other coupling constants are associated with other unique particles, which have their own array of energies and interaction peculiarities; their own amplitudes and probability densities; their own values. One other example I will mention is the gravitational coupling constant.
To remove anthropological bias, physicists often set certain constants such as the speed of light (c), the reduced Planck constant (ℏ) , the fundamental force constant (e), and the Coulomb force constant (4πε)equal to “one”. Sometimes the removal of human bias in the values of the constants can help to reveal relationships that might otherwise go unnoticed.
The coupling constants for gravity and fine-structure are two examples.
for gravity;
for fine-structure.
These relationships pop-out of the math when extraneous constants are simplified to unity.
Despite their differences, one thing turns out to be true for all coupling constants — and it’s kind of surprising. None can be derived or worked out using either the theory or the mathematics of quantum mechanics. All of them, including the fine-structure constant, must be discovered by painstaking experiments. Experiments are the only way to discover their values.
Here’s the mind-blowing part: once a coupling constant — like the fine-structure alpha (α) — is determined, everything else starts falling into place like the pieces of a puzzle.
The fine-structure constant, like most other coupling constants, is a number that makes no sense. It can’t be derived — not from theory, at least. It appears to be the magnitude of the square of an amplitude (which is a complex, multi-dimensional number), but the fine-structure constant is itself one-dimensional; it’s a unit-less number that seems to be irrational, like the number π.
For readers who don’t quite understand, let’s just say that irrational numbers are untidy; they are unwieldy; they don’t round-off; they seem to lack the precision we’ve come to expect from numbers like the gravity constant — which astronomers round off to four or five decimal places and apply to massive objects like planets with no discernible loss in accuracy. It’s amazing to grasp that no constant in nature, not even the gravity constant, seems to be a whole number or a fraction.
Based on what scientists think they know right now, every constant in nature is irrational. It has to be this way.
Musicians know that it is impossible to accurately tune a piano using whole numbers and fractions to set the frequencies of their strings. Setting minor thirds, major thirds, fourths, fifths, and octaves based on idealized, whole-number ratios like 3:2 (musicians call this interval a fifth) makes scales sound terrible the farther one goes from middle C up or down the keyboard.
Jimi Hendrix, a veteran of the US Army’s 101st Airborne Division, rose to mega-stardom in Europe several years before 1968 when it became the American public’s turn to embrace him after he released his landmark album, Electric Ladyland. Some critics today say that Jimi remains the best instrumentalist who has ever lived. Mr. Hendrix achieved his unique sound by using non-intuitive techniques to tune and manipulate string frequencies. Some of these methods are described in the previous link. It is well worth the read.
No, in a properly tuned instrument the frequencies between adjacent notes differ by the twelfth root of 2, which is 1.059463094…. . It’s an irrational number like “π” — it never ends; it can’t be written like a fraction; it isn’t a ratio of two whole numbers.
In an interval of a major fifth, for example, the G note vibrates 1.5 times faster than the C note that lies 7 half-steps (called semitones) below it. To calculate its value, take the 12th root of two and raise it to the seventh power. It’s not exactly 1.5. It just isn’t.
Get out the calculator and try it, anyone who doesn’t believe.
[Note from the Editorial Board: a musical fifthis often written as 3:2, which implies the fraction 3/2, which equals 1.5. Twelve half-notes make an octave; the starting note plus 7 half-steps make 8. Dividing these numbers by four makes 12:8 the same proportion as 3:2, right? The fraction 3/2 is a comparison of the vibrational frequencies (also of the nodes) of the strings themselves, not the number of half-tones in the interval.
However, when the first note is counted as one and flats and sharps are ignored, the five notes that remain starting with C and ending with G, for example, become the interval known as a perfectfifth. It kind of makes sense, until musicians go deeper; it gets a lot more complicated. It’s best to never let musicians do math or mathematicians do music. Anyone who does will create a mess of confusion, eight times out of twelve, if not more.]
An octave of 12 notes exactly doubles the vibrational frequency of a note like middle C, but every note in between middle C and the next higher octave is either a little flat or a little sharp. It doesn’t seem to bother anyone, and it makes playing in large groups with different instruments possible; it makes changing keys without everybody having to re-tune their instruments seem natural — it wasn’t as easy centuries ago when Mozart got his start.
The point is this:
Music sounds better when everyone plays every note a little out of tune. It’s how the universe seems to work too.
As for gravity, it works in part because space-time seems to curve and weave in the presence of super-heavy objects. No particle has ever been found that doesn’t follow the curved space-time paths that surround massive objects like our Sun.
Notice the speed of the hands of the clocks and how they vary in space-time. Clocks slow down when they are accelerated or when they are immersed in the gravity of a massive object, like the star at the center of this GIF. Click on it for a better view.
Even particles like photons of light, which in the vacuum of space have no mass (or electric charge, for that matter) follow these curves; they bend their trajectories as they pass by heavy objects, even though they lack the mass and charge that some folks might assume they should to conduct an interaction.
Massless, charge-less photons do two things: first, they stay in their lanes — that is they follow the curved currents of space-time that exist near massive objects like a star; they fall across the gravity gradient toward these massive objects at exactly the same rate as every other particle or object in the universe would if they found themselves in the same gravitational field.
Second, light refracts in the dielectric of a field of gravity in the same way it refracts in any dialectric—like glass, for example. The deeper light falls into a gravity field, the stronger is the field’s refractive index, and the more light bends.
Measurements of star-position shifts near the edge of our own sun helped prove that space and time are curved like Einstein said and that Isaac Newton‘s gravity equation gives accurate results only for slow moving, massive objects.
Massless photons traveling from distant stars at the speed of light deflect near our sun at twice the angle of slow-moving massive objects. The deflection of light can be accounted for by calculating the curvature of space-time near our sun and adding to it the deflection forced by the refractive index of the gravity field where the passing starlight is observed.
In the exhilaration of observations by Eddington during the eclipse of 1919 which confirmed Einstein’s general theory, Einstein told a science reporter that space and time cannot exist in a universe devoid of matter and its flip-side equivalent, energy. People were stunned, some of them, into disbelief. Today, all physicists agree.
The coupling constants of subatomic particles don’t work the same way as gravity. No one knows why they work or where the constants come from. One thing scientists like Freeman Dyson have said: these constants don’t seem to be changing over time.
Evidence shows that these unusual constants are solid and foundational bedrocks that undergird our reality. The numbers don’t evolve. They don’t change.
Confidence comes not only from data carefully collected from ancient rocks and meteorites and analyzed by folks like Denys Wilkinson, but also from evidence uncovered by French scientists who examined the fossil-fission-reactors located at the Oklo uranium mine in Gabon in equatorial Africa. The by-products of these natural nuclear reactors of yesteryear have provided incontrovertible evidence that the value of the fine-structure constant has not changed in the last two-billion years. Click on the links to learn more.
Since this essay is supposed to describe the fine-structure constant named alpha (α), now might be a good time to ask: What is it, exactly? Does it have other unusual properties beside the coupling forces it helps define during interactions between electrons and photons? Why do smart people obsess over it?
I am going to answer these questions, and after I’ve answered them we will wrap our arms around each other and tip forward, until we lose our balance and fall into the rabbit hole. Is it possible that someone might not make it back? I suppose it is. Who is ready?
Alpha (α) (the fine-structure constant) is simply a number that is derived from a rotating vector (arrow) called an amplitude that can be thought of as having begun its rotation pointing in a negative (minus or leftward direction) from zero and having a length of .08524542…. . When the length of this vector is squared, the fine-structure constant emerges.
It’s a simple number — .007297352… or 1 / 137.036…. It has no physical significance. The number has no units (like mass, velocity, or charge) associated with it. It’s a unit-less number of one dimension derived from an experimentally discovered, multi-dimensional (complex) number called an amplitude.
We could imagine the amplitude having a third dimension that drops through the surface of the graph paper. No matter how the amplitude is oriented in space; regardless of how space itself is constructed mathematically, only the absolute length of the amplitude squared determines the value of alpha (α).
Amplitudes — and probability densities calculated from them, like alpha (α) — are abstract. The fine-structure constant alpha (α) has no physical or spatial reality whatsoever. It’s a number that makes interaction equations balance no matter what systems of units are used.
Imagine that the amplitude of an electron or photon rotates like the hand of a clock at the frequency of the photon or electron associated with it. Amplitude is a rotating, multi-dimensional number. It can’t be derived. To derive the fine structure constant alpha (α), amplitudes are measured during experiments that involve interactions between subatomic particles; always between light and electricity; that is, between photons and electrons.
I said earlier that alpha (α) can be written as the fraction “1 / 137.036…”. Once upon a time, when measurements were less precise, some thought the number was exactly 1 / 137.
The number 137 is the 33rd prime number after zero; the ancients believed that both numbers, 33 and 137, played important roles in magic and in deciphering secret messages in the Bible. The number 33 was Christ’s age at his crucifixion. It was proof, to ancient numerologists, of his divinity.
The number 137 is the value of the Hebrew word, קַבָּלָה (Kabbala), which means to receive wisdom.
In the centuries before quantum physics — during the Middle Ages — non-scientists published a lot of speculative nonsense about these numbers. When the numbers showed up in quantum mechanics during the twentieth century, mystics raised their eyebrows. Some convinced themselves that they saw a scientific signature, a kind of proof of authenticity, written by the hand of God.
That 137 is the 33rd prime number may seem mysterious by itself. But it doesn’t begin to explain the mysterious properties of the number 33 to the mathematicians who study the theory of numbers. The following video is included for those readers who want to travel a little deeper into the abyss.
Numerology is a rabbit-hole in and of itself, at least for me. It’s a good thing that no one seems to be looking at the numbers on the right side of the decimal point of alpha (α) — .036 might unglue the too curious by half.
Read right to left (as Hebrew is), the number becomes 63 — the number of the abyss.
I’m going to leave it there. Far be it for me to reveal more, which might drive innocents and the uninitiated into forests filled with feral lunatics.
Folks are always trying to find relationships between α and other constants like π and e. One that I find interesting is the following:
=
Do the math. It’s mysterious, no?
Well, it might be until someone subtracts
which brings the result even closer to the experimentally determined value of α. Somehow, mystery diminishes with added complexity, correct? Numerology can lead to peculiar thinking e times out of π. Right?
People’s fascination with the fine-structure constant has led to many unusual insights, such as this one, found during an image search on the web. The hypotenuse is 137.036015… .
The view today is that, yes, alpha (α) is annoyingly irrational; yet many other quantum numbers and equations depend upon it. The best known is:
These constants (and others) show up everywhere in quantum physics. They can’t be derived from first principles or pure thought. They must be measured.
As technology improves, scientists make better measurements; the values of the constants become more precise. These constants appear in equations that are so beautiful and mysterious that they sometimes raise the hair on the back of a physicist’s head.
The equations of quantum physics tell the story about how small things that can’t be seen relate to one another; how they interact to make the world we live in possible. The values of these constants are not arbitrary. Change their values even a little, and the universe itself will pop like a bubble; it will vanish in a cosmic blip.
How can a chaotic, quantum house-of-cards depend on numbers that can’t be derived; numbers that appear to be arbitrary and divorced from any clever mathematical precision or derivation?
The inability to solve the riddles of these constants while thinking deeply about them has driven some of the most clever people on Earth to near madness — the fine-structure constant (α) is the most famous nut-cracker, because its reciprocal (137.036…) is so very close to the numerology of ancient alchemy and the kabbalistic mysteries of the Bible.
What is the number alpha (α) for? Why is it necessary? What is the big deal that has garnered the attention of the world’s smartest thinkers? Why is the number 1 / 137 so dang important during the modern age, when the mysticism of the ancient bards has been largely put aside?
Well, two reasons come immediately to mind. Physicists are adamant; if α was less than 1 / 143 or more than 1 / 131, the production of carbon inside stars would be impossible. All life we know is carbon-based. The life we know could not arise.
The second reason? If alpha (α) was less than 1 / 151 or more than 1 / 124, stars could not form. With no stars, the universe becomes a dark empty place.
These are the values of some of the fundamental constants mentioned in this essay. Plug them into formulas to confirm they work, any reader who enjoys playing with their calculator. It’s clear that these numbers make no precisional sense; their values don’t correspond to anything one might find on any list of rational numbers. It’s possible that they make no geometric sense, either. If so, then God is not a mathematician.
Without mathematics, humans have no hope of understanding the universe.
Yet, here we are wrestling against all the evidence; against all the odds that the mysteries of existence will forever elude us. We cling to hope like a drowning sailor at sea, praying that the hour of rescue will soon come; we will blow our last breath in triumph; humans can understand. Everything is going to fall into place just as we always knew it would.
It might surprise some readers to learn that the number alpha (α) has a dozen explanations; a dozen interpretations; a dozen main-stream applications in quantum mechanics.
The simplest hand-wave of an explanation I’ve seen in print is that depending on ones point of view, “α” quantifies either the coupling strength of electromagnetism or the magnitude of the electron charge. I can say that it’s more than these, much more.
One explanation that seems reasonable on its face is that the magnetic-dipole spin of an electron must be interacting with the magnetic field that it generates as it rushes about its atom’s nucleus. This interaction produces energies which — when added to the photon energies emitted by the electrons as they hop between energy states — disrupt the electron-emitted photon frequencies slightly.
This jiggling (or hopping) of frequencies causes the fine structure in the colors seen on the screens and readouts of spectrographs — and in the bands of light which flow through the prisms that make some species of spectrographs work.
OK… it might be true. It’s possible. Nearly all physicists accept some version of this explanation.
Beyond this idea and others, there are many unexplained oddities — peculiar equations that can be written, which seem to have no relation to physics, but are mathematically beautiful.
For example: Euler’s number, “e” (not the electron charge we referred to earlier), when multiplied by the cosine of (1/α), equals 1 — or very nearly. (Make sure your calculator is set to radians, not degrees.) Why? What does it mean? No one knows.
What we do know is that Euler’s number shows up everywhere in statistics, physics, finance, and pure mathematics. For those who know math, no explanation is necessary; for those who don’t, consider clicking this link to Khan Academy, which will take you to videos that explain Euler’s number.
What about other strange appearances of alpha (α) in physics? Take a look at the following list of truths that physicists have noticed and written about; they don’t explain why, of course; indeed, they can’t; many folks wonder and yearn for deeper understanding:
1 — One amazing property about alpha (α) is this: every electron generates a magnetic field that seems to suggest that it is rotating about its own axis like a little star. If its rotational speed is limited to the speed of light (which Einstein said was the cosmic speed limit), then the electron, if it is to generate the charge we know it has, must spin with a diameter that is 137 times larger than what we know is the diameter of a stationary electron — an electron that is at rest and not spinning like a top. Digest that. It should give pause to anyone who has ever wondered about the uncertainty principle. Physicists don’t believe that electrons spin. They don’t know where their electric charge comes from.
2 — The energy of an electron that moves through one radian of its wave process is equivalent to its mass. Multiplying this number (called the reduced Compton wavelength of the electron) by alpha (α) gives the classical (non-quantum) electron radius, which, by the way, is about 3.2 times that of a proton. The current consensus among quantum physicists is that electrons are point particles — they have no spatial dimensions that can be measured. Click on the links to learn more.
3 — The physics that lies behind the value of alpha (α) requires that the maximum number of protons that can coexist inside an atom’s nucleus must be less than 137.
Think about why.
Protons have the same (but opposite) charge as electrons. Protons attract electrons, but repel each other. The quarks, from which protons are made, hold themselves together in protons by means of the strong force, which seems to leak out of the protons over tiny distances to pull the protons together to make the atom’s nucleus.
The strong force is more powerful than the electromagnetic force of protons; the strong force enables protons to stick together to make an atom’s nucleus despite their electromagnetic repulsive force, which tries to push them apart.
An EM force from 137 protons inside a nucleus is enough to overwhelm the strong forces that bind the protons to blow them apart.
Another reason for the instability of large nuclei in atoms might be — in the Bohr model of the atom, anyway — the speed that an electron hops about is approximately equal to the atomic number of the element times the fine-structure constant (alpha) times the speed of light.
When an electron approaches velocities near the speed of light, the Lorentz transformations of Special Relativity kick in. The atom becomes less stable while the electrons take on more mass; more momentum. It makes the largest numbered elements in the periodic table unstable; they are all radioactive.
The velocity equation is V = n * α * c . Element 118 — oganesson — presumably has some electrons that move along at 86% of the speed of light. [ 118 * (1/137) * (3E8) ] 86% of light-speed means that relativistic properties of electrons transform to twice their rest states.
Uranium is the largest naturally occurring element; it has 92 protons. Physicists have created another 26 elements in the lab, which takes them to 118, which is oganesson.
When 137 is reached (most likely before), it will be impossible to create larger atoms. My gut says that physicists will never get to element 124 — let alone to 137 — because the Lorentz transform of the faster moving electrons grows by then to a factor of 2.3. Intuition says, it is too large. Intuition, of course, is not always the best guide to knowledge in quantum mechanics.
Plutonium, by the way — the most poisonous element known — has 94 protons; it is man-made; one isotope (the one used in bombs) has a half-life of 24,000 years. Percolating plutonium from rotting nuclear missiles will destroy all life on Earth someday; it is only a matter of time. It is impossible to stop the process, which has already started with bombs lost at sea and damage to power plants like the ones at Chernobyl and at Fukushima, Japan. (Just thought I’d mention it since we’re on the subject of electron emissions, i.e beta-radiation.)
4 — When sodium light (from certain kinds of streetlamps, for example) passes through a prism, its pure yellow-light seems to split. The dark band is difficult to see with the unaided eye; it is best observed under magnification.
The split can be measured to confirm the value of the fine-structure constant. The measurement is exact. It is this “fine-structure” that Arnold Sommerfeld noticed in 1916, which led to his nomination for the Nobel Prize; in fact Sommerfeld received eighty-four nominations for various discoveries. For some reason, he never won.
5 — The optical properties of graphene — a form of carbon used in solid-state electrical engineering — can be explained in terms of the fine-structure constant alone. No other variables or constants are needed.
6 — The gravitational force (the force of attraction) that exists between two electrons that are imagined to have masses equal to the Planck-mass is 137.036 times greater than the electrical force that tries to push the electrons apart at every distance. I thought the relationship should be the opposite until I did the math.
It turns out that the Planck-mass is huge — 2.176646 E-8 kilograms (the mass of the egg of a flea, according to a source on Wikipedia). Compared to neutrons, atoms, and molecules, flea eggs are heavy. The ratio of 137 to 1 (G force vs. e force) is hard to explain, but it seems to suggest a way to form micro-sized black holes at subatomic scales. Once black holes get started their appetites can become voracious.
The good thing is that no machine so far has the muscle to make Planck-mass morsels. Alpha (α) has slipped into the mathematics in a non-intuitive way, perhaps to warn folks that, should anyone develop and build an accelerator with the power to produce Planck-mass particles, they will have — perhaps inadvertently — designed a doomsday seed that could very well grow-up to devour Earth, if not the solar system and beyond.
8 — The Standard Model of particle physics contains 20 or so parameters that cannot be derived; they must be experimentally discovered. One is the fine-structure constant (α), which is one of four constants that help to quantify interactions between electrons and photons.
9 — The speed of light is 137 times greater than the speed of “orbiting” electrons in hydrogen atoms. The electrons don’t actually “orbit.” They do move around in the sense of a probability distribution, though, and alpha (α) describes the ratio of their velocities to the cosmic speed limit of light. (See number 3 in this list for a description of element 118 — oganesson — and the velocity of some of its electrons.)
10 — The energy of a single photon is precisely related to the energy of repulsion between two electrons by the fine-structure constant alpha (α). Yes, it’s weird. How weird? Set the distance between two electrons equal to the wavelength of any photon. The energy of the photon will measure 137.036 times more than the repulsive force between the electrons. Here’s the problem. Everyone thinks they know that electron repulsion falls off exponentially with distance, while photon energy falls off linearly with wavelength. In these experimental snapshots, photon energy and electron repulsive energy are locked. Photons misbehave depending on how they are measured, right? The anomaly seems to have everything to do with the geometric shape of the two energy fields and how they are measured. Regardless, why “α”?
11 — The charge of an electron divided by the Planck charge — the electron charge defined by natural units, where constants like the speed of light and the gravitational constant are set equal to one — is equal to . This strange relationship is another indicator that something fundamental is going on at a very deep level, which no one has yet grasped.
12 — Some readers who haven’t toked too hard on their hash-pipes might remember from earlier paragraphs that the “strong force” is what holds quarks together to make protons and neutrons. It is also the force that drives protons to compactify into a solid atomic nucleus.
The strong force acts over short distances not much greater than the diameter of the atom’s nucleus itself, which is measured in femtometers. At this scale the strong force is 137 times stronger than the electromagnetic force, which is why protons are unable to push themselves apart; it is one reason why quarks are almost impossible to isolate. Why 137? No one has a clue.
Now, dear reader, I’m thinking that right now might be a good time to share some special knowledge — a reward for your courage and curiosity. We’ve spelunked together for quite a while, it seems. Some might think we are lost, but no one has yet complained.
Here is a warning and a promise. We are about to descend into the deepest, darkest part of the quantum cave. Will you stay with me for the final leg of the journey? I know the way. Do you believe it? Do you trust me to bring you back alive and sane?
In the Wikipedia article about α, the author writes, In natural units, commonly used in high energy physics, where ε0 = c = h/2π = 1, the value of the fine-structure constant is:
Every quantum physicist knows the formula. In natural units e = .302822….
Remember that the units collapse to make “α” a dimensionless number. Dimensional units don’t go away just because the values used to calculate the final result are set equal to “1”, right? Note that the value above is calculated a little differently than that of the Planck system — where 4πε is set equal to “1”.
As I mentioned, the value for “α” doesn’t change. It remains equal to .0073…, which is 1 / 137.036…. What puzzles physicists is, why?
What is the number 4π about? Why, when 4π is stripped away, does there remain only “α” — the mysterious number that seems to quantify a relationship of some kind between two electrons?
Well… electrons are fermions. Like protons and neutrons they have increments of 1/2 spin. What does 1/2 spin even mean?
It means that under certain experimental conditions when electrons are fired through a polarized disc they project a visible interference pattern on a viewing screen. When the polarizing disc is rotated, the interference pattern on the screen changes. The pattern doesn’t return to its original configuration until the disc is rotated twice — that is, through an angle of 720°, which is 4π radians.
Since the polarizer must be spun twice, physicists reason that the electron must have 1/2 spin (intrinsically) to spin once for every two spins of the polarizer. Yes, it makes no sense. It’s crazy — until it isn’t.
What is more insane is that an irrational, dimensionless number that cannot be derived by logic or math is all that is left. We enter the abyss when we realize that this number describes the interaction of one electron and one photon of light, which is an oscillating bundle of no one knows what (electricity and magnetism, ostensibly) that has no mass and no charge.
All photons have a spin of one, which reassures folks (because it seems to make sense) until they realize that all of a photon’s energy comes from its so-called frequency, not its mass, because light has no mass in the vacuum of space. Of course, photons on Earth don’t live in the vacuum of space. When photons pass through materials like glass or the atmosphere, they disturb electrons in their wake. The electrons emit polaritons, which physicists believe add mass to photons and slow them down.
The number of electrons in materials and their oscillatory behavior in the presence of photons of many different frequencies determine the production intensity of polaritons. It seems to me that the relationship cannot be linear, which simply means that intuition cannot guide predictions about photon behavior and their accumulation of mass in materials like glass and the earth’s atmosphere. Everything must be determined by experiment.
Theories that enable verifiable predictions about photon mass and behavior might exist or be on the horizon, but I am not connected enough to know. So check it out.
Anyway… frequency is the part of Einstein’s energy equation that is always left out because, presumably, teachers feel that if they unveil the whole equation they won’t be believed — if they are believed, their students’ heads might explode. Click the link and read down a few paragraphs to explore the equation.
In the meantime, here’s the equation:
When mass is zero, energy equals the Planck constant times the frequency. It’s the energy of photons. It’s the energy of light.
Photons can and do have any frequency at all. A narrow band of their frequencies is capable of lighting up our brains, which have a strange ability to make sense of the hallucinations that flow through them.
Click on the links to get a more detailed description of these mysteries.
What do physicists think they know for sure?
When an electron hops between its quantum energy states it can emit and absorb photons of light. When a photon is detected, the measured probability amplitude associated with its emission, its direction of travel, its energy, and its position are related to the magnitude of the square of a multi-dimensional number. The scalar (α) is the probability density of a measured vector quantity called an amplitude.
When multi-dimensional amplitudes are manipulated by mathematics, terms emerge from these complex numbers, which can’t be ignored. They can be used to calculate the interference patterns in double-slit experiments, for one thing, performed by every student in freshman physics.
The square root of the fine-structure constant matches the experimentally measured magnitude of the amplitude of electron/photon interactions — a number close to .085. It means that the vector that represents the dynamic of the interaction between an electron and a photon gets “shrunk” during an interaction by almost ten percent, as Feynman liked to describe it.
Because amplitude is a complex (multi-dimensional) number with an associated phase angle or direction, it can be used to help describe the bounce of particles in directions that can be predicted within the limitations of the theory of quantum probabilities.
Square the amplitude, and a number (α) emerges — the one-dimensional, unit-less number that appears in so many important quantum equations: the fine-structure constant.
Why? It’s a mystery. It seems that few physical models that go beyond a seemingly nonsensical vision of rotating hands on a traveling clock can be conjured forth by the brightest imaginations in science to explain the why or how.
The fine-structure constant, alpha (α) — like so many other phenomenon on quantum scales — describes interactions between subatomic particles — interactions that seem to make no intuitive sense. It’s a number that is required to make the equations balance. It just does what it does. The way it is — for now, at least — is the way it is. All else is imagination and guesswork backed by some very odd math and unusual constants.
By the way (I almost forgot to mention it): α is very close to 30 times the ratio of the square of the charge of an at-rest electron divided by Planck’s reduced constant.
Anyone is welcome to confirm the calculation of what seems to be a fairly precise ratio of electron charge to Planck’s constant if they want. But what does it mean?
What does it mean?
Looking for an answer will bury the unwary forever in the rabbit hole.
I’m thinking that right now might be a good time to leave the abyss and get on with our lives. Anyone bring a flashlight?
There is no genetic code. Not really. Not in the way most people think. Seasoned, sensible geneticists know it’s true.
Unfortunately, a few immature biologists don’t believe it. They are developing “gene drive” technologies that they hope will enable them to reliably and permanently alter a fragment of “the code” in any life-form that reproduces sexually — to guarantee that the altered piece of “code” will be transmitted to the next generation 100% of the time into perpetuity.
NOTE TO READERS:November 22, 2019: This essay is the longest on the website. To help readers navigate, The Editors asked Billy Lee to add links to important subtopics. Don’t forget to click the up arrow on the right side of the page to return to top.
Deployment of gene-drive technology means that an altered fragment of genetic code can be “injected” into a species, for good or ill, which is permanent and will over a few generations become universal — unable to be suppressed or removed regardless of any natural selection pressures whatsoever — until the end of time.
The changes caused by gene drivers takeover every individual in any species that has been targeted for modification. It takes about 10 generations, give or take. With insects, we’re talking a couple of years; plants, a decade maybe; humans, 300 years or so.
Gene drivers are all about changing an entire species forever and permanently — not just one individual with a genetic disorder, for example, or one generation of plants for another. It’s a higher level of intervention than conventional gene therapies and modifications.
A screw-up can extinguish a species in a relatively short period of time is how I see the danger. Worse, according to the scientists cited by the NYTimes, these genes will migrate into ecological niches, where they will force unintended consequences to the biosphere; worse still, given sufficient time “good” genes are likely to jump species, where they will wreak havoc.
EDITORS NOTE: On 18 September 2020 the website science-news service phys.org published an article titled Biologists Create New Genetic Systems toNeutralize Gene Drives.
According to the article:
The first neutralizing system, called e-CHACR (erasing Constructs Hitchhiking on the Autocatalytic Chain Reaction) is designed to halt the spread of a gene drive by “shooting it with its own gun.” e-CHACRs use the CRISPR enzyme Cas9 carried on a gene drive to copy itself, while simultaneously mutating and inactivating the Cas9 gene.
The system can in principle be placed anywhere in the genome.
The second neutralizing system, called ERACR (Element Reversing the Autocatalytic Chain Reaction), is designed to eliminate the gene drive altogether. ERACRs are designed to be inserted at the site of the gene drive, where they use the Cas9 from the gene drive to attack either side of the Cas9, cutting it out. Once the gene drive is deleted, the ERACR copies itself and replaces the gene-drive.
Both systems have been tested in the lab at a molecular level. The developers have not yet demonstrated that a gene drive screw-up gone wild can be pulled back and eliminated by these systems.
The good news is that scientists are working on the problem. The bad news is that the existence of infant, untested technologies might tempt some to release a gene drive into the wild that will ultimately prove intractable.
EDITORS NOTE: On 6 March 2021 the website science-news service phys.org published an article titled New ‘split-drive’ system puts scientists in the (gene) driver seat. The piece describes new split-gene-drive technology that promises to degrade over several generations to permit engineered genomes to evolve under the rules of natural selection. Such a system, if safely deployed, would help to prevent collapse-of-species and other bad consequences when mistakes are made.
If anybody doesn’t understand what they just read, they shouldn’t worry. By the end of this essay, they will fully grasp why the scientists pursuing this course might be dangerously eager to unleash genetic pollutants that may kill us all — because their love of science makes it difficult to restrain themselves.
Virus stands on cell surface. It will soon inject it’s RNA payload into the cell to take control of its genetic machinery.
These smart people (some might be prodigies for all I know) plan to use gene drivers to exterminate vermin and eradicate insect-borne disease, for starters. They plan to make it impossible for agricultural pests to develop resistance to pesticides.
It all sounds great. But so did using the by-products of nuclear bombs as an energy source for our cities. Ask Japan how their state-of-the-art nuclear energy program turned out. Ask about Fukushima.
Gene-drive technologies are an existential threat to the long-term survival of life on Earth — like those tens-of-thousands of plutonium-loaded thermonuclear missiles, which a number of countries have buried a few hundred feet below the surface of the earth.
The warheads on these missiles are going to rot someday, because no one can take care of them forever, and we can’t get rid of them. Their poisons — the most lethal known; a speck of plutonium dust can kill any human who ingests it — will leach into the soils; over thousands of years percolating plutonium will kill everything.
Genes — bad ones (or very good ones that turn out bad; oops!) — genes that can never die; genes that can’t be suppressed by natural selection; genes that are always passed on to the next generation under every conceivable scenario and every possible pairing of mates (no matter how mismatched) present potential nightmare scenarios for any species that possess them. Errant gene drivers can extinguish some species in a matter of a few years.
It is distressing to think that smart, young adults — I can imagine some younger than 35 who possibly lack basic common-sense — does it matter how smart they are? — might right now be playing around with molecules of DNA they can’t possibly understand fully, because the molecules have a quantum side to their nature that can make their behavior unpredictable; even unknowable.
Young adults are messing around with very complicated structures and processes inside both molecules and cells that they can’t see, even with the best microscopes and the most sophisticated instruments. It’s possible that they might — even with the best intentions; the best lab protocols — screw things up big-time and possibly forever. We need maximum oversight over these researchers and the labs who employ them, now — not tomorrow or next year.
Click on this link to an essay in the science journal Nature, which addresses the issue of gene-driver risk and its management. It is written by someone who seems, at least to my mind, to suggest remedies that are insufficiently robust.
Every biologist knows that “genes” have a mysterious way of migrating between species, crossing boundaries, and behaving unpredictably. They have a way of escaping confinement structures. If folks don’t understand why, what are they doing playing around and calling it research?
Editors Note (May 27, 2017):Here is a link to a May 17, 2017 article in Science News about the role of jumping genes in the expression of genomes, which may be of interest to some readers.
People have claimed for years that recombinant DNA pathogens, retro-viruses and yes, AIDS, escaped from rogue laboratories. Does anyone know for sure? If they do, they aren’t saying.
Anyway, I urge readers to relax for now in the knowledge that they are about to learn some amazing things. I did, writing this essay. And please remember: I am a pontificator, not a scientist.
Links are provided to verify anything written in the essays that people may question. My pledge to readers is, as always, to be as accurate as possible and to correct mistakes should I discover them or find myself corrected by others.
Yes, I can be smart and write good too. Well, I’m trying anyway. Getting it right is important. It’s my highest priority. But sometimes I screw up — usually on some arcane technical detail in an essay about science.
Sometimes the science changes and new facts emerge. When I first published this essay in May 2016 everyone thought the galaxies in the universe numbered 200 billion. As I add this note in May 2018, analysis of the latest pics from telescopes in space suggests that the number of galaxies is closer to two-trillion.
My pledge is to keep my essays up-to-date and to learn enough to fix screw-ups that might be caused by simple ignorance. Readers can help fix errors by sending corrections in comments. Errors in the text will be fixed immediately.
So far, we’ve been lucky. The number of errors identified is amazingly few. In one doozy, I published the picture of a well-known British actress (well-known in Britain) and said it was Rosalind Franklin, the X-ray crystallographer famous for making the images that hinted at the spiral staircase structure of DNA.
Celebrities in Europe (that is, in England) were kind enough to take the time to inform me how wrong I was. I appreciated the feedback and was grateful they didn’t kill me.
I’m joking. The Brits are the kindest and best-behaved people on Earth. I’ve spent enough time in London to know.
The genetic code that everyone talks about lives inside tiny spaces; one way to think about it is to imagine that it lives inside little rooms packed to the ceiling with sacks — bitty-bags stuffed full of strung-together bases — hiding in the center of every cell of every plant and animal (or disbursed throughout the cell in the case of most one-celled microbes).
It isn’t a code at all. It’s a reservoir; an inventory; a collection of templates — most broken into pieces; separated and scattered among the dozens of spiral tentacles in the vast aperiodic-crystal known as DNA.
DNA isn’t exactly a crystal either; not really. Crystals are structures made from regular (periodic) arrangements of molecules. DNA, on the other hand,isa molecule, and it is constructed from strings of chemical bases. It’s found in bundles alongside other DNA molecules. These bundles are called chromosomes.
During part of a cell’s life cycle these DNA strings can sometimes be found tightly wound around little pieces of protein like fishing lines around spinning-reels. It’s a configuration that makes them compact; less intrusive — but easier to see under a microscope when they have been stained.
Inside any particular cell each chromosome of DNA is in some ways a little like a snowflake; within a single cell, no two chromosomes are the same; no two are alike, not even close. But every cell in the body contains the same group of chromosomes; the chromosomes in each body-cell are identical to the chromosomes in every other body-cell, right? It’s not hard to understand.
Bases, by the way, (in case someone might be wondering) are chemical substances that turn into salts when acids are poured over them. Many bases exist in nature, but only four (nucleobases) are found in DNA.
These four bases are essentially one or two rings of nitrogen and carbon atoms with ammonia and vinegar-like side chains attached. Here are links for anyone who wants to look them up: adenine – thymine ; and cytosine – guanine.
A fifth base, uracil substitutes for thymine in RNA, which is a vast assortment of short, single-stranded, DNA-like segments — the cell’s worker-ants who enable cells to perform their many functions. RNA builds genes, moves stuff around, and dramatically speeds up cell chemistry by catalyzing thousands of processes.
Not to digress, but NASA found uracil on the surface of Saturn’s moon Titan in 2012 during a fly-by. It’s something to wonder about.
Caffeine is molecularly similar to the bases adenine and guanine. Bases taste bitter — like the caffeine in coffee. Acids, on the other hand, taste sour — like vinegar. Combine bases and acids (bitter and sour) chemically to make salts, which are substances that taste like the ocean.
This tangled mess is one-celled life, highly magnified. It is varied, imprecise, and invisible to humans. It takes about ten of these microbes (which are about the size of human red-blood cells) to span the width of a human hair; 30 to circumnavigate it. DNA is far smaller. It requires 8,000 tightly wound DNA bundles to span a human hair; 800 to span the length of one of these microbes.
Forgive me for starting simple. Life-sciences are the most complicated sciences of all.
What adds to the difficulty is that in most animals (and all people) the DNA involved in sexual reproduction is configured differently than the DNA in body-cells. It exhibits behaviors a little less like those found in other cells.
In this essay we are talking about animal DNA, usually human, in body-cells — somatic cells; and we are talking about protein production.
A single DNA group inside certain humanbody-cells like liver cells and stem cells (while they undergo the process of replicating and dividing) is composed of ninety-two large molecules called DNA strands, which together warehouse the six billion base-pairs that will populate the genomes of two daughter cells.
During the short-lived interval when cells divide and replicate, dozens of molecules and billions of bases gather themselves into the configuration of chromosome-pairs peculiar to people, which some of us learned about in high school biology.
Most of the time (90% of it anyway) DNA doesn’t divide and multiply; it doesn’t organize itself into easy to recognize chromosomes; in all body-cells except stem cells and liver cells, DNA is the starting material for the making of proteins instead.
Making proteins is the only thing most body-cells do; it starts in the DNA molecules and is the subject of this essay. Cell division and replication is what stem cells do. Links will lead to those subjects for any who might want to learn more.
This essay is not about stem cells, which develop into any and every kind of somatic (body) cell and germ (reproductive) cell. As a pontificator who is not an expert on stem cells, my understanding is that — except for liver cells — somatic cells in mature adults don’t generally divide and reproduce themselves. That function is performed by stem cells, which start at conception and continue through life to replenish the human body.
Stem cells live inside the tissues of adults like seasonings inside cooked beef, is how I imagine it. Check me on this one, experts. Correct me in the comments section. All others read this link on cell differentiation first.
The main point is that human body-cells house 46 chromosomes (called chromatids when they are organized into 23 connected pairs), which contain six billion base-pairs. Reproductive (germination or germ) cells contain 23 unpaired chromosomes that store three billion base-pairs.
Confusing terminology constructed from the Greek language can create stumbling blocks for non-scientists, so I’m reluctant to go there. Terms like diploid, haploid, gamete, and zygote folks can look up and explore on their own. There’s enough that’s fascinating in English. Only tiny, digestible Greek lessons — sparsely sprinkled — will appear in this essay.
Besides unfamiliar vocabulary, another hard concept to grasp is this: inside every animal cell (and plant cell) are hundreds of DNA packed bundles (called mitochondria), where the DNA is not like the DNA in sex-cells or in body-cells either. The DNA in mitochondria matches what one might expect to find in another as yet undiscovered species of bacteria. It’s “coded” differently.
Yes, it’s weird, but there are explanations.
Most scientists today believe that a long time ago cells engulfed bacteria; these foreign migrants from another world (in terms of scale) were simply unable to escape.
Bacteria are small. A thimble-full of dirt can contain 50,000 species. It is amazing to learn that millions of species of bacteria exist in the soils and on the surfaces of plants on the earth.
Thirty-percent of cells in the human body are bacteria. They don’t weigh much, because they are small. It would require as many as 10,000 individuals of some strains to match in size just one of the microbes displayed in the illustration a few paragraphs above.
On average, though, a typical cell in an animal or plant can be visualized as having about 4,000 times the volume of a typical bacterium. The range of volume ratios varies widely, of course. Nothing is simple, especially in biology. Enough said.
Scientists named the trapped bacteria-like life-forms inside cells, mitochondria, afterthe Greek words for threaded granules; these granulesmake the cells they inhabit more robust, because they act like little batteries, boosting the energy in their adopted homes to help power the many tasks that cells do. Click the video link above for an animation by Harvard University that shows how it works.
Click the link above for an easy-to-understand animation of the overall structure of cells; or this link for a YouTube Video designed to transport viewers through an imaginary, animated world that makes real the complexity of a working, living cell.
And here is a link from Wikipedia, if anyone is confused about the numbers of bases and chromosomes in humans, as many folks seem to be, including myself, sometimes.
It’s confusing, because there are different “codes”, different cell-cycle phases, different collections of DNA molecules in body, germ, and stem cells — and I haven’t even mentioned enzyme catalysis or polymerases (and I’m not going to, either — not just yet anyway — because it will open a big can of worms I don’t want to deal with right now).
Don’t worry, we’ll get to some of it later after I’ve laid a little scaffolding.
But let me say this: without all this complexity, life forms as complicated as human beings would be impossible — codes or no codes.
The tools most people use to do science, especially physics, generally depend on mathematics and rigid, predictable rules. The life-sciences aren’t like that; not at all.
Should my essay devolve into complexity, readers are free to bail. I’m going to try to keep the mysteries of DNA understandable to non-technical people. Who knows if I’ll succeed or not?
DNA can be thought of as a collection of pouches or bags stuffed with billions of copies of four basic substances, called bases. DNA is like a roomful of holiday bags, each filled to the brim with four different kinds of unfinished toys like the ones in Santa’s workshops before Christmas.
Each of the four kinds of toys are strung together in-line, one after the other — in no discernible order — in long, tangled spirals. These spirals are unimaginably long, and there are many dozens of them.
The toys in the DNA sacks are unfinished, unpainted, and undecorated. They really don’t look much like toys at all. In this analogy, the four bases might be imagined as four simple blocks of wood, each a different shape and size. And like I said, there are billions of these blocks, at least in human cells.
Is DNA a big molecule? Yes, I already said that it was. It’s huge. But good luck to anyone who tries to find one. Good luck to anyone who tries to look at one. No one has ever seen any molecule. No matter how large, molecules are too small to see, even with microscopes; and that includes DNA molecules, the largest and most complex molecules in biology.
It takes a combination of high-energy light, amplification, and computer-generated algorithms to produce useful pictures of what scientists think molecules look like. A computer-generated image is not the same as a brain-generated image stimulated by the act of looking at reflected light with a pair of human eyes.
X-ray crystallography was the technique used first to unravel clues to the structure of DNA. From the data collected by crystallography, Linus Pauling shared in 1951 compelling ideas about what he thought the structure was, but he turned out to be wrong. He got protein structure right, but his description of DNA had subtle errors. A few years later, others came up with a structure that has thus far stood the test of time.
In soma (body) cells, forty-six molecules (strands or bags or sacks) of DNA contain the six billion base-pairs (or blocks) of the human genome. Most of the time these strands are loose and disorganized; a diffuse mass of hard-to-see chromatin. (Their form depends on what part of its period the cell cycle is in.)
It has to be this way for the worker elves of the cell to gain access to the bases (the unfinished toy blocks) upon which they will do their work. Only during the process of cell division do these forty-six molecules bind together and curl-up into the twenty-three chromosome-pairs that some readers may have learned about in high school biology class.
Researchers have technologies that can amplify what DNA molecules reveal, which they manipulate with computer algorithms to form fuzzy pictures that are helpful to highly trained analysts; but it’s the best they can do, visually.
An early theorist, Erwin Schrödinger, (one of my heroes) said in 1944 — before anyone knew what DNA was — that it must be an aperiodic-crystal. He gave a series of lectures, which later became the famous booklet, What is Life? It can be purchased for fifteen bucks on Amazon.com.
Schrödinger’s booklet changed the world — it’s one of the most prophetic works I’ve ever read. The tract changed my world view anyway; my view of life certainly.
It turns out, Schrödinger was right. DNA bundles store billions of bases in more-or-less random — but frozen — sequences much like crystals.
Just as molecules arrange themselves inside crystals, the bases inside DNA molecules also have an order, yes, an arrangement for sure, but it’s not a code; it’s not even a cipher; it’s merely a starting point for the most chaotic, complex, and messed-up process in nature — the creation of thinking, speaking, conscious-life (and less capable life) — all formed from a relatively few not-so-simple materials.
Here’s another assertion that might be difficult for some readers to accept. Genes don’t really exist. There are no free-standing genes; certainly not in human DNA, anyway. What scientists call genes must be constructed; they must be built; they must be put together; they must be fabricated, collected, and transported by molecules called RNA and by other processes known collectively as epigenetics. More on epigenetics later.
(Click on this old graphic (from 2004) to get a clearer view.) This illustration is a simplified representation of the chaos going on during arguably one of the simplest of the processes (transcription), which is the starting point for encoding other processes (called translation) that will ultimately lead to the fabrication and folding of proteins.
Most graphics and videos on the Internet seem to buy into a tidy notion that DNA is a code (not a reservoir and a starting point for the fabrication of templates). This notion seems to demand laser-precision and machine-like twelve-sigma reliability during protein synthesis.
Don’t believe it.
Yes, there is no argument; we can improve our chances for healthier lives by cleaning up less-than-optimal base-sequences — which are, as often as not, scattered, scrambled hodgepodges — using, hopefully, gene therapies like CRISPR. (Clustered Regularly Interspaced Short Palindromic Repeats)
But until technicians create tools to deal with other processes; until biologists can manipulate RNA itself and learn to change the ”weather” patterns (discussed later) inside cells, physicians will not be able to eliminate many of pathologies that plague our species and lead to diminished health and, for some, death.
RNA in all its forms (and there are many) is itself constructed from scattered templates that are hidden haphazardly like Easter eggs within the billions of bases strewn along the dozens of spirals inside a DNA bundle. RNA first builds itself up by interacting with various sections of base sequences in the DNA and then copies those sequences by borrowing matching freebases, which are floating everywhere in the medium of the cell’s nucleus.
RNA is much shorter in length and less stable than the DNA it models. But it doesn’t mutate as much as folks might expect, because it is also shorter-lived and reproduces less often. It’s more versatile too; more agile, because it is single-stranded; DNA is double-stranded.
RNA, in all its forms, is the workhorse of cell functions; it is both the building material and the construction machinery used in many important cell structures, which perform the yeoman’s task of protein building inside cells.
It seems plausible to me that over a few hundreds-of-millions of years the possibly self-generated RNA sequences may have acquired — through accident, luck, or trial-and-error — the ability to select, copy, paste, and assemble short sections of random DNA bases, which every-once-in-a-great-while actually worked to help build useful proteins that added survival advantages to their evolving hosts.
Maybe RNA designed and built DNA in the first place, which it learned to copy and manipulate. We may never know exactly how.
One thing scientists agree on: one-celled life was already highly developed, complex, and flourishing by the time the new planet, Earth, reached its first billionth year. Earth is four-and-a-half billion years old. Life came on fast during extreme conditions vastly different than now. This fact is amazing. No one understands how.
It has taken an additional three-and-a-half billion years to get to humans and the space-traveling civilizations that seem to dominate the earth today.
Thinking about RNA and DNA can be a frustrating circular process, much like the chicken or the egg problem; which came first? My sense is that most scientists today believe RNA came first, DNA later. Inside our cells, it is impossible to tell, but there is no denying that RNA’s diversity and flexibility make it a most likely candidate.
Many kinds of RNA live inside cells. Some run around doing nothing. They simply try to survive inside the complicated universe that is the typical living cell in every animal, plant, and microbe. They are called selfish RNA.
Most RNA sequences are much less selfish. They are like Christmas elves who work day and night; some to open Santa’s bags to gain access to their contents; others to copy various sections from the strands of blocks inside; others to move the copied sections to an assembly area, where other elves glue the copied segments together to form new sequences — many of which, by the way, are very different from the original sequences that the RNA elves found inside Santa’s gift bags; inside the DNA.
Eventually, messenger elves transport the long strands of little blocks they copied and assembled; they move them away from the center of the cell; out to the gooey regions of the cell beyond its center where other transfer elves are busy assembling (by threes) free-floating blocks (called bases, remember) and attaching these triplet-blocks (called anticodons) to single amino acids. The resulting structures are called transfer RNA (or tRNA, for short).
An amino acid is simply a configuration of carbon atoms with amine (ammonia) stuck to one side and carboxylic acid (vinegar) stuck to another — plus some other simple stuff attached here and there to make each amino acid unique among all the others. Think of an amino acid as a colored necklace bead. Out of the five-hundred or so differently colored beads in nature, transfer elves in humans work with only twenty or so.
Stay with me now. You just read the most difficult sentence in the essay. These amino acids attach themselves like colorized necklace beads to triplet-blocks (called anticodons) according to which of the three blocks (or bases) the transfer-RNA (tRNA) is made from. Watch the video ”From DNA to protein” above to better understand.
In the meantime, while all this other stuff is going on, the messenger elves are directing their long strands of copied-and-pasted blocks (bases) away from the cell’s tiny nucleus (center) toward little triplet-body-handling factories (called ribosomes; ribo for triplet, soma for body), which live in the inner goo (the cytoplasm) of the cell.
Many ribosomes are attached to a winding ribbon-like structure called the rough endoplasmic reticulum. Endo is Greek for inner; plasma is goo; reticulum means network.
At the same time, transfer elves in the goo (cytoplasm) steer their three-blocks-plus-a-colored-beadassemblies — in humans these “three-base” combos and twenty or so colored beads can be arranged forty-eight ways — into the ribosome factories, where they are matched-up to the blocks (bases) in the long strands that are being delivered from the cell’s nucleus (like cars in a choo-choo train) by the messenger elves.
Inside the ribosome factories, the triplet-blocks-plus-one-colored-bead assemblies, which have been constructed and collected by the transfer elves in the cytoplasm, are paired block for block (that is, base for base) to the long train of blocks that were collected, arranged, and carried by the messenger elves from the cell’s center (its nucleus).
As each transfer assembly triplet is matched-up three bases at a time to the blocks in the long messenger train, the single amino-acid bead that the three-block transfer assembly carries is ejected out of the ribosome factory.
Assembly elves — think of them as molecular forces — secure each ejected amino acid bead to the next bead, one after the other — in the exact order demanded by the order (in threes, called codons when located in the messenger RNA) of the bases (blocks) in the messenger sequence — creating as they go an amino-acid-chain, or necklace.
Once the amino acid chain (necklace) is long enough (and remember: there can be as many as twenty-three different colors of amino-acid beads in each necklace, and each necklace can be almost any length at all — up to hundreds or even tens-of-thousands of beads long) elves (molecular forces that work through the micro-scaffolding of the cell) go to work; they transfer the chains to Golgi structures, where they are bundled and folded into the twisted shapes that make them proteins. Like an Amazon distribution center, the Golgi apparatuses deliver the proteins to their destinations.
Like holiday elves, they deliver protein toys to every child’s bedroom in the cell, which in this analogy lie inside the abyss of the cell’s cytoplasm (cyto means cell; plasm means goo).
Some elves might feel compelled to deliver their proteins down the street to other homes (cells) in other neighborhoods by way of certain processes known as cell migrations.
These migrations can bring healing to injured tissues in other parts of the body, among other benefits. However, as I wrote earlier, stem cells that live inside the tissues of the body do the heavy lifting of cell replacement and healing.
Here is a way to visualize a human cell: think of cytoplasm (the cell goo) as the yolk of an idealized egg. A chicken egg is nothing like a human body-cell, but it makes a good model for explanations.
(Click on pic to enlarge.) This drawing is an idealized view of a typical eukaryotic cell, which in this essay is compared to the yolk of a chicken egg. The egg-white is the thin plasma membrane.
The nucleolus (at the epicenter) is a tiny, hard to find collection of proteins, RNA, and DNA at the very center of the nucleus where ribosomes are fabricated, if anyone wonders.
Ribosomes are made entirely from RNA; they are, in fact, one of the most ancient structures in cells; they are essential players in both prokaryotic and eukaryotic (ancient and modern) cells, which I will discuss in more detail soon.
Chromatin (the usually unorganized mess of DNA) lies in the nuclear goo of the nucleus that surrounds the nucleolus.
Remember that ribosomes are the tiny factories, where proteins get their start. Ribosomes themselves move between the nucleolus and the surrounding nuclear goo until they are ejected out of the pores of the nucleus into the goo of the yolk (which in this analogy is the cytoplasm) where many will float freely in an ocean filled with a dozen or more other structures important to cell functions. Many ribosomes attach themselves to the endoplasmic reticulum.
But we’re not concerned about these other structures right now. Proteins are the most essential substances from which our bodies are made.
Some biologists believe that as many as 50,000 different proteins are required to construct a human being. Others say 100,000. The human body is capable of producing two million. Each cell type on its own is capable of making 5,000.
Ribosomes are very important, because it is inside the ribosomes where proteins get started, so we concentrate on them first.
Think of the cell’s membrane as the “white” of the egg. It surrounds and protects the vital cytoplasm, where the making of proteins takes place.
Of course, the chicken egg analogy had to break down. A chicken egg is surrounded by an oxygen-permeable calcium carbonate (CaCO3) shell. Forget about the shells of chicken eggs. Human soma-cells aren’t protected in quite the same way.
In a chicken egg the nucleus is a little white mass that sits on top of the yolk and feeds on it. The nucleolus is inside that little white mass. So the breakfast-egg analogy falls apart pretty darn fast. It might be more confusing than helpful. I hope not.
A lot more is going on. And — I have to say this — the cells of most microbes (one-celled life, like bacteria and archaea) don’t look like the sunny-side-up cells of humans or most other animals and plants. For one thing, they are a lot smaller.
Bacteria and archaea can be from 20 to 10,000 times smaller than the eukaryotic cells of animals and plants. They lack membrane-bound organelles; they lack a nucleus. They look more like little sandwich bags of loosely cooked, scrambled eggs. Scientists call them, prokaryotes. (It’s Greek, meaning before they became fully formed kernels.) They are the ancient cells.
As for the other structures that live inside our own eukaryotic cells (again, it’s Greek, meaning after they became kernels) — they make a fascinating study, but are beyond the scope of this essay.
Eukaryotes are the modern more advanced cells of all plants and animals. It took two billion years for ancient prokaryotic cells to evolve to the modern eukaryotic cells that first appeared 1.5 billion years ago; it is these cells that congregated and evolved to become the plants and animals of today. Click on the links in this essay — such as the links in nearby paragraphs — to access Wikipedia articles, YouTube videos, and other sources to learn more about them.
Phosphoric acid, which people have used for centuries to remove rust and to fertilize crops makes the DNA supports (or strands) on which hang the rungs of billions of bases. Phosphoric acid is the concentrated, clear syrup that makes Coca-Cola sting the tongue (carbon-dioxide bubbles make Coke sparkle). It’s the acid found inside the nucleus of every cell.
Apatite crystal from Mexico.
Hundreds of years ago phosphoric acid was made from the stone mineral apatite (calcium phosphate) and sulphuric acid — by-products of the mining and smelting of ores. Today the production process is more arcane and efficient.
Phosphorus is arguably one of the most important elements of life. Only magnesium is more important to viability, because the ATP that powers all cells will not work unless it is bound to it. Folks who aren’t eating whole wheat, spinach, black beans, almonds, and peanuts should probably be taking a daily magnesium supplement.
People who eat steak consume goodly amounts of phosphoric acid. Early researchers always found this acid in the center of cells, their nucleus. Scientists called it, nucleic acid.
Much later scientists discovered that the DNA sacks were full of bases, crammed together into tangled masses of long, curly chains they called chromosomes (Greek, for coloredbodies).
Chromosomes stained well during lab experiments, which was fortunate for researchers, because color made it easier to see the chromosomes during the short periods of time when the genetic material in the cell’s center took on its distinctive form from out of the shapeless, invisible chromatin, where it lived.
It is by a curious twist of chemical engineering — to my mind, at least — that the bases don’t react with the phosphoric acid that anchors them. The DNA molecules don’t collapse into little piles of salt, like one might expect. Maybe they should; but on Earth, they don’t.
In this sense — the sense in which our DNA is made from acids and bases — we are salt, or could be; we are potentially a very complicated salt, yes, but a salt nonetheless.
A strong argument can be made that proteins and the polypeptide chains that make them are in fact salts. For reasons known only to biochemists, naming conventions hide this reality.
Amino acids, polypeptides, and proteins are thought of as inner salts and given the name zwitterions, of all things. Salt is at the heart of what and who we might become were it not for idiosyncrasies of nomenclature and the miracle that makes life live.
But to get back to phosphoric acid…
Phosphoric acid (phosphate) sacks (or strands) are loaded with toy blocks (bases), so they need something sticky, like sugar, to keep the blocks from falling out. The D in DNA stands for the sticky stuff — deoxyribose, which means sugar.
This simplified graphic shows sticky sugar (deoxyribose) securing the phosphate rails of a DNA strand to the only two kinds of base-pairs found in DNA — thymine / adenine and guanine / cytosine. The sugar, deoxyribose, forms both a link and a buffer between the acid and the bases; otherwise, the molecule would collapse to become a salt. DNA breaks down completely at 374° Fahrenheit, which is just 72° above the melting point of table sugar. An interesting comparison is the melting point of table salt, which is 1474°F.
DNA is deoxyribonucleic acid.
The sugar and acid, together, form the rails of the famous spiral staircase, upon which the rungs of bases are hung. It’s the most incredible structure in nature. It’s called the double-helix. Some people named Watson, Wilkins, and Crick won a Nobel Prize for figuring it out.
To give readers a sense of scale: If someone were to take the longest strand of the double-helix in our DNA (it’s in chromosome-one) and somehow increased its diameter to one-inch (the thickness of a large garden hose), the DNA strand — when pulled straight — would increase in length to 567 miles (about 40 miles longer than the distance between Nashville and Detroit).
The bases (or toy blocks, as we’ve been calling them) would stack in pairs, eight-pairs-to-the-inch, along the entire 567-mile length of the hose. In this single chromosome, each of the nearly half-billion bases it contains (in 247,199,719 base-pairs) would be about the size of a Tic-Tac breath mint; maybe a bit smaller.
At normal scales, the dimensions are too fantastic to believe. A solitary strand of DNA can’t be seen, even with the aid of most microscopes, but if all the DNA in a single cell could be laid out end to end and flattened to remove the kinks, it would stretch to six-and-a-half feet. 6.5 feet is the length of all the DNA in a typical human cell.
According to Siri, 1E14 cells make a human. It’s “one” followed by 14 zeros. It’s 100 trillion. Other sources say no; the number of cells in a human being is between 15 and 70 trillion. A trillion has twelve zeroes, right?
Do the math. It will show that all the DNA in a single human is enough to spin a strand from the earth to the sun and back 99 to 662 times (which is somewhere between 198 and 1324 astronomical units, right?) depending on who is trusted to do the human cell-count. Does anyone believe it?
An astronomical unit (AU) is simply the distance from the Earth to the Sun. It is the distance traveled by light during 499 seconds, which is 8 minutes and 19 seconds. It’s close to 93 million miles, right?
The point is this: strands of DNA are too thin to see, but in humans their total length is on an astronomical scale that spans two-and-half to sixteen-and-a-half times the diameter of the solar system out to Pluto — a diametral orbital distance that is nearly 80 AU.
It’s a lot of DNA, even if the exact amount is uncertain.
Rosalind Franklin (1920-1958). Franklin received her PhD from Cambridge University at age 25. (Her thesis: The physical chemistry of solid organic colloids with special reference to coal.) Franklin spoke several languages, which opened opportunities for her to work in France, where she acquired the skills in X-ray crystallography that enabled her to advance the world to a new understanding of viruses and the molecules of life — DNA.
Rosalind Franklin, the gifted X-ray crystallographer, who did the experimental research that led to the discovery of the double helix, died of ovarian cancer at age 37. The Nobel Prize Committee has a long-standing policy of not awarding prizes to people who have died. It’s why Irish physicist and mathematician John Stewart Bell didn’t receive a prize for his civilization-changing work on quantum-entanglement, after he suffered a brain hemorrhage and perished in 1990.
In Franklin’s case it was doubly sad, because she was also doing important work on the molecular structure of viruses related to polio (funded by the United States Public Health Service) when cancer overtook her. Once again another scientist — this time her partner, Aaron Klug — received the Nobel Prize that she might have shared.
Had Rosalind Franklin survived to receive two Nobel Prizes — one for her work on the double helix and the other on the structure of polio virus — she would be a household name, like Albert Einstein or Francis Crick or Jonas Salk.
Rosalind lived in a generation and a culture that devalued her; she was a woman who competed with men, some of whom may have undercut her and wanted nothing to do with her, a few admitted. It was a different time, the 1950s. Who knows where the truth lies?
For Franklin, fame-and-fortune wasn’t to be. Blame cancer, a disease of the “genes”, which she sacrificed her life to understand by working daily with the deadly X-rays that helped her unlock the secrets of viruses and, most important of all, to finally pull aside the opaque curtain that was hiding the shape of the molecule of life: DNA.
Once the structure of the double-helix became known, the potential to store information in a molecular bundle constructed like DNA was immediately recognized — and it appeared to be unlimited. It is why everyone at first thought that the DNA molecule must be a code, like an old-fashioned computer tape.
I’ve suggested that DNA is not a code; neither is it a cipher. Some researchers view DNA more as a storage device and a starting point for processes — complicated processes — that have taken place inside every living cell for 3.5 billion years.
Yes, a group of three bases and an attached amino acid, properly transformed and manipulated by RNA elves inside little protein-making workshops called ribosomes, can help to fabricate and string together colored beads to make necklaces (chains). Chains of amino acids (polypeptides) — properly ordered and folded, again by RNA elves — can become proteins.
Scattered DNA base sequences inside a cell’s nucleus, its center, are a starting point for an involved and complicated process of selection, duplication, transformation, and fabrication before anything useful can happen; before proteins can be built and released for living.
To think realistically about life, especially human life, people should remind themselves that two-thirds of their bodies is water; two-thirds of what’s left is protein; the rest is mostly fat.
The interior of a cell is a complicated space. The space between cells is other-worldly.
The process that goes on inside cells, instead of being thought of as a precisely executed computer code, might better be compared to the process of weather found on every planet in the solar system.
Each planet can be identified by its surface weather, which starts from a kit of basic materials, and is amplified by an avalanche of environmental conditions and chemistries, much like the bases in chromosomes, which are selected, copied, shaped and reshaped, configured and reconfigured by RNA elves and other characters we have yet to meet (because the science of the evolving genome — the genetic material — and the phenome — what animals and plants look like — is still young, and scientists understand less than the little they think they know about the complete process, at least so far).
The processes used to construct life forms by starting with the bases in DNA are analogous to the processes astronomers observe on the planets of our solar system, where each planet creates its weather from the matrix of materials and thermal conditions that seems to define it. Each planet in the solar system has a characteristic weather profile that depends on a chaotic interplay of materials and environment unique to that planet.
Earth has weather; so does Mars and Jupiter. Those who study planets know immediately which planet is which, simply by observing its weather. From telescopes on Earth, each planet looks like its weather. Each has its characteristic colors and patterns. Weather is a planet’s phenotype; it’s what folks see when they look.
This mammoth storm on Jupiter looks eerily like structures that are found in living cells. The inset is planet Earth, shown for scale.
That’s how it is with life forms, too. Each life form is the result of weather patterns inside cells, which give each animal, plant, and microbe its unique essence; its physical presence in the larger world where it lives.
It becomes conventional wisdom to think this way about life forms, when one considers that identical twins — two humans who share exactly the same DNA — always display a variety of differences when examined closely.
Identical twins never have the same fingerprints, for example. There are systems of weather occurring around their genetic material in every protein-producing region in their bodies. Epigenetics is the technical term for the study of how it is that variations in phenomes occur in organisms that have identical genomes — that is, identical gene sequences.
Click pic for larger view in new window. (from Wikipedia article, Epigenetics)
The outcomes of these storms are never the same; two supposedly identical children do not always receive the same toys from the RNA elves who rummage through their shared bags (strands) of DNA for the bases they will copy and rework into proteins. Things get mixed up and turned around. One toy gets selected; another doesn’t; one is painted green; another purple.
What I find interesting is this: identical twins get less identical as they age. They are easier to distinguish.
How many of the differences are due to variations in the production of proteins, which occur at the molecular level?
How much of the variation is induced by external stresses on the genome caused by lifestyle differences? How much is driven by an unavoidable drift in the statistics of protein production, which emerge and diverge over time in each phenome of the twins regardless of their lifestyle choices?
An animal cannot be constructed from its DNA alone. RNA elves — millions of them, like colonies of ants — must do their work.
It’s a chaotic process that produces life on the earth. It’s a process that cannot be described or predicted by mathematics. If it could, scientists might take the DNA from prehistoric bones to create the original animals. Jurassic Park would be more than a Hollywood fantasy, which is what the book, movie, and sequels were and are.
An animal cannot be constructed from its DNA alone. A lot more is required than a simple collection of sequences formed from four bases and frozen in a molecule of DNA. A lot more of life’s machinery is required. The RNA elves — millions of them, like colonies of ants — must do their work.
When the work is done, and a protein has been made and delivered, the path back is lost, forever. No way exists — or is even possible — to reconstruct the sequence of bases in the DNA that started the process that built the protein. The process is not backward compatible, according to Matthew Cobb, the British zoologist and historian, in his latest book, Life’s Greatest Secret. Not only are the DNA sequences not reachable from knowledge of the proteins alone, but the processing steps that took place between the protein and the DNA are unknowable.
I don’t want to get too Mathy but think about this: sixty-four three-block (or three-base) sequences can in theory “code” for a mere twenty or so amino acids. It means that as many as three or four of those three-base sequences (the transfer elves we talked about earlier) can “code” for the same amino acid.
Reminder: four bases are all the choices DNA offers. Taken three at a time, they are more than enough to “code” for twenty or so amino acids. Get out the calculator, those who don’t believe it. 4 X 4 X 4 = 64. As mentioned earlier, humans have acquired over the eons 48 three-base combinations to work with. Bacteria, for another example, have 31 according to Matthew Cobb. We need less than two dozen.
Amino acid sequences long enough to form proteins can be hundreds to tens-of-thousands of acids long.
Forget about how amino acid chains get folded properly to make proteins. How can anyone work backwards from a protein formed from thousands of amino-acid beads — each one of which was secured to any one of three or four different 3-way combinations of bases (or blocks) — and then go about the task of reconstructing from all those possible combinations the exact sequence of bases (or blocks) in the original DNA, which more than a few random RNA sequences interacted with to make their choices from billions of bases in the first place?
Take a breath. There isn’t enough time in the history of the universe to figure it out for the tens-of-thousands of proteins that it takes to make a functioning animal or plant.
Raise the number “three” (or four, or five, or six, or two; it doesn’t matter) to the thousandth power on a calculator, those who may be having trouble accepting a possibly demoralizing fact. Most calculators will spit out the word, OVERFLOW. The number of possible sequences is impossibly large. It might as well be infinite.
This is the genetic code. I guess I should show it. (Click the pic for a clearer view.) A lot of folks worked on it; it was a pinch point; a roadblock that once slowed progress toward the understanding of what makes life live; how cells behave. Now that it’s known, is anyone sure it is the only code? The answer is, no. Variations have already been found in nature — at least 15 so far with more expected as researchers continue their work.
It seems likely that the ”code” has changed in dramatic ways since the first primitive cells formed 3.5 billion years ago. British zoologist, Matthew Cobb, has suggested that words like ”code” and ”information” might better be thought of as mere metaphors when applied to the machinations of complex molecules like DNA and RNA, which — can we admit? — operate on quantum scales for which we humans have no natural intuition.
There are thousands of chains of all different lengths and folding patterns. No one is going to reverse-engineer the DNA of a life-form as complex as a human being from its proteins; nor from its RNA elves; nor from its essential enzymes and catalysts; not anytime soon; not ever. It goes for dinosaurs, trees, or any other reasonably complex living thing — now or from the distant past.
Why do we have to reverse-engineer? Why not read the instructions right off the DNA itself? By now most readers must be starting to understand that the sequences necessary to build proteins are scattered among billions of bases. We can’t find the right ones in the right order. It’s not possible; not for creatures as complex as humans or dinosaurs.
Even if someone could reverse-engineer DNA sequences from proteins, how would they construct and organize the ant-like colonies of RNA elves that must sort through the DNA bases to select and build the right sequences; how do they identify and isolate the sequences necessary to build and orchestrate, for example, the tens-of-thousands of enzymes that are required to give researchers any chance at all to build a functioning human-being or even a prehistoric dinosaur?
It gets more complicated.
Those who don’t believe it might want to read about CNVs, or copy number variations, that disrupt the probabilities that certain base-sequences in genes can be fabricated in the same way time after time. Click the link.
It’s a form of change that has nothing to do with mutations or inheritance. It is more related to the untidy mess that three billion base pairs make whenever they get together to do anything at all. It’s a genetic Woodstock of variation, where almost anything can happen and sometimes does.
Now might be a good time to mention that there are virus infections that can alter the DNA in cells. These viruses are called retroviruses, because they reverse the DNA to RNA transcription process described earlier by introducing an enzyme into the cells they infect. This process is disease producing — it causes cancer — and destroys the host animal (or person) if left untreated.
The enzyme, reverse transcriptase, has become a tool that molecular engineers now use to modify organisms in experiments. Enough said. The weeds of molecular biology grow thick and deep.
This is the inverse genetic code. I might as well show it, too. (Click the pic for a clearer view.) Tables like this one make the ”code” appear to be comprehensive and far-reaching. Some readers might be surprised to learn that only one or two percent of the bases in human DNA are ever copied by RNA to make proteins.
Tables like the one above make the ”code” appear comprehensive and far-reaching. Some readers might be surprised to learn that only one or two percent of the bases in human DNA are ever copied by RNA to make proteins.
Added to 2% for protein synthesis is 8% to make little pieces of RNA that oversee and coordinate the process of protein-making — like colonies of swarming ants. The rest of the bases (90%) do other things; maybe — many of them — do nothing at all. No one is really sure what they do or don’t do.
Geneticists used to believe they could clone animals from their DNA sequences alone. Yes, there once was a cloned sheep named Dolly. Some readers may have read about her.
After many heart-breaking failures, researchers managed to take the DNA from the mammary gland of one sheep, inject it into the nucleus of an egg from a second sheep, and implant this DNA cocktail into the womb of a third. By some miracle, Dolly was conceived and born, on July 5, 1996.
Dolly (5 July 1996 – 14 Feb 2003). Pic by Tony Barros, Sao Paulo, Brazil.
Sheep live twelve years, on average. By Dolly’s fourth year arthritis crippled her. At year seven researchers euthanized her; she had developed a chronic and incurable lung disease.
Dolly was the recipient of arguably the best healthcare any sheep ever received in the history of veterinary medicine. She didn’t do well. Click this link for an update on the Dolly research.
For the sake of complete accuracy, permit me to admit that no one I know clones sheep anymore. There are too many failures. The failure rate for clones is right around 100%.
Some breeders claim to clone horses, which they sell to folks who hope to increase their odds of winning races. I can argue that their definition of cloning differs from science, and the proof is that the horses have noticeable differences which negatively impact their ability to win.
Clone researchers, as far as anyone knows, have never used DNA alone, anyway. All borrow the enzymes, RNA, ribosomes, and other cell structures of other life forms to incubate the DNA they play with to try to create “artificial” life.
Mitochondrial DNA is unreachable. It is produced only in the ovum of the female. Mitochondrial DNA carried by sperm is miniscule in amount and quickly identified and destroyed in the fertilized egg.
Any technique that involves in vitro fertilization can bypass this natural process and inadvertently scramble the DNA in mitochondria. It can be debilitating, even disease producing.
Any technique that swaps out nuclear DNA while avoiding mitochondrial DNA doesn’t get to the power source of cells — a major enabler of stamina and endurance. In racehorses, the role of mtDNA is probably crucial, it seems to me.
My point is that duplicating a DNA sequence is not enough to produce an identical copy of an animal as complex as a sheep, horse, or human. Too much other stuff is going on during reproduction that is not controllable or even known.
And speaking of enzymes, can we please not go there? I’m reminded of Chris Farley in the 1992 movie, Almost Heroes.
Does anyone remember?
His tutor asks him to learn the symbol for lowercase A. ”What do you want from me?” Chris bellows while rolling his eyes and clawing his hair. ”You want my head to explode?!”
Well, no, of course not. But for those who have to know more, why not push ourselves just a little bit harder? May I point out the obvious? Enzymes speed up chemical reactions. A chemical reaction that might under normal circumstances take years can be reduced to milliseconds by an optimally configured enzyme.
Some enzymes are made from RNA; most are proteins; in fact, most proteins are enzymes; they all get their start from sequences of bases hidden deep within the mountains of DNA inside our cells. These bases are selected, copied, and transformed into their many convoluted shapes for a very special reason: to help accelerate over 5,000 processes inside cells.
Without these highly specialized structures, metabolism would grind to a halt; DNA and RNA would acquire all the mobility of a conga-line of standing stones; cell processes would freeze into a petrified forest of non-living complexity. Life as we know it would be impossible, code or no code.
This is XNA. I’m told it’s less messy and easier to manipulate than DNA. It’s very good at being loaded with code and used as a storage device for information.
Here is a good question: Has any research team ever created artificial life in a laboratory?
Craig Venter, who has been interviewed on 60 Minutes and appeared in several Ted Talks videos, says that he has. He oversees a number of research labs funded by big oil and the government. His labs write computer code to generate base sequences, which they construct and then inject into yeast (among other techniques) to produce life-forms that they hope will someday lead to biofuels and greenhouse gas inhibitors.
Among other accomplishments, one of the labs, the Craig Venter Institute, is known to have introduced a gene from the bacteria, escherichia coli, into the earth’s toughest microbe, “Conan the Bacterium” (Deinococcus radiodurans), to create microbes that can detoxify radioactive wastes at nuclear facilities.
So, the answer to the question about whether anyone has ever created artificial life must be, probably not, not really — not from scratch, anyway. Yes, people have done amazing things. No one has created life without using existing life to do it, though. The process is too complex. On Earth, it has taken 4.5 billion years.
Many argue that life fell to Earth from the stars. Even Earth itself might not have been able to ignite the spark that led to humans and all the life we know.
In 2012 a different group of researchers did find a way to arrange a set of different bases inside DNA-like molecules called XNA. But it was a way of coding sequences only; it didn’t produce or even arrange proteins into anything that could be called, alive.
The “X” stands for the Greek word, Xeno, which means “other.” XNA is other nucleic acid.
An informed reader told me that in fact a protein was made from a sequence of XNA in 2015. If true, the future of genetics could get interesting in coming decades.
XNA is at the very least the precursor, many hope, for long-term storage of massive amounts of information in small, stable molecules — demanded now by data-churning behemoths such as CERN, home of the world’s most powerful particle-collider, located in Geneva, Switzerland.
Just because artificially constructed molecules like XNA can store useful information does not mean that DNA does the same. People have imagined meaning into the bases of DNA, which they simply don’t have — to help better understand their function and to more effectively manipulate them — for good or ill.
Another development in 2012, which some readers may remember, is that researchers learned to use a process known by the acronym CRISPR to change the sequence of bases in stretches of DNA. They adapted an immunization process that bacteria use to kill viruses and defend against subsequent attacks.
Click on the pic to open a more readable image in another tab.
Bacteria use CRISPR to suck the DNA out of an attacking virus, which they store in a kind of library for future reference. If a bacterium survives and the virus dies, somehow the bacteria is able to develop a quick-kill strategy that it will use whenever it is invaded by more DNA that matches a copy in its collection.
Researchers learned to create novel CRISPR DNA based on the system used by bacteria. They then attached RNA guides and cas9 protein shears to the sequences. They learned to deploy the assemblies to search and destroy bad DNA; and to insert designer DNA in its place in the cells of plants and animals; even humans.
These scientists insist that gene “therapies” are necessary, because the fact is: DNA is defective — most of it, anyway. Very few humans are symmetrical, attractive, disease-free, smart, emotionally stable, long-lived, or any other desirable trait anyone might want that is driven by how humans are built, or how they are “coded” at a molecular level.
Crisper video published October 25, 2019 on YouTube.
Gene drivers (mentioned in the first paragraphs of this article) are being developed in coordination with CRISPR techniques to enable changes to DNA molecules that will be permanent and transmittable 100% of the time. Their success will depend on how well lab technicians understand what is going on inside the molecules of life; and inside our cells.
Editor’s note:In January 2018 some researchers admitted that problems related to positional locating have created a roadblock to success for CRISPR technologies. They hope to solve the difficulties soon to avoid a catastrophic failure in the application of this heralded gene-altering process. One process under development that seems to promise more precision and speed is to use electro-magnetic positioning in place of viruses.
I believe we need to slow down and learn more before we unleash immortal genes into the biosphere that no one can pull back and which may turn out to be harmful despite best intentions. Asilomar style conferences that lead to best-practice regulations with the force of international law behind them are desperately needed to control biotechnologies that are quickly getting out-of-hand and beyond the control or understanding of government and politicians.
It is quite certain that PCR technology (polymerase chain reactionamplification), which scientists use to amplify into a viewable goo the molecules of DNA-style life might be misleading folks into believing that DNA-style life is all there is.
Earth could be infested with non-DNA based life, but no one will know until other technologies capable of detecting and amplifying it are developed and perfected.
People need to remind themselves that we are talking about molecules here — molecules of life that can’t be seen — even with help of the most sophisticated microscopes. Everything science knows comes from amplification techniques and mathematical analyses. I hope someday to write an essay on the techniques scientists use to tease out what they know for sure about these next-to-impossible-to-observe molecules.
Serious scientists refer to the possibility for the existence of non-DNA style life as the “shadow biosphere.” If this non-DNA life interacts with our own in a symbiotic way, the potential for harm, it seems to me, increases the more lab technicians play around with molecules they don’t fully understand while they remain oblivious to life they can’t detect, because they lack appropriate laboratory tools and techniques.
An even messier problem is “dark DNA”. It’s DNA that can’t be found, though tests clearly show it must exist for certain cell processes to work right.
Some researchers argue that as many as twenty thousand proteins are manufactured in humans that, when they search the human genome, they can’t find the sequences that are required to be there, somewhere, to enable the proteins to be built. I urge readers to click this link to learn more about this potentially serious inability of sequencers to decode DNA accurately and completely.
No one knows what they don’t know; and what they don’t know can kill us all, if lab workers aren’t cautious. Researchers know they don’t know stuff — important stuff if they intend to play around with gene drivers and CRISPR induced gene sequencing.
Researchers might be walking through a genetic minefield but are so eager to cross that they ignore the dangers of amputated limbs; the loss of sight and hearing; the possibilities for disfigurement to the genomes and phenomes of species like our own, which all people may one day come to regret.
No human is perfect. Sometimes our imperfections are caused not by bad stretches of DNA but by naughty RNA elves who copy less than optimal sections of bases, which they hammer together into less-than-optimal genes, which can screw-up a sequence of amino acids. The RNA elves end up making defective proteins that pollute cells, damage our bodies, and make our lives miserable.
To the extent that these screw-ups are the result of a lousy sequence of bases in our DNA, perhaps these patterns will be able to be altered using CRISPR technology (if anyone can get it to work right), which is likely to increase the odds of inducing better outcomes. But many screw-ups, perhaps most, are not caused by poorly sequenced genes constructed from DNA.
Many problems result from bad choices made by some arbitrary RNA elf, for example, who might have decided, perhaps, to cut and paste a random mix of bad sections it rummaged from the DNA strands; its errors and mistakes might not always be able to be located, identified, and repaired successfully. Renegade RNA elves are hard to track down and kill; at least so far.
Some problems can be caused by all kinds of things not related to DNA, like temperature, quantum effects, and cosmic radiation, including sunlight. The number of things that can go wrong with the weather-environment inside cells is enormous. Copy number variations in gene sequencing is another problem area that I mentioned earlier.
Safety and reliability are probably the two most important reasons why our haystacks of six-billion DNA bases hide a mere twenty-one thousand so-called genes, most of which are scattered in pieces throughout our vast DNA bundled-network.
Those few sequences that are important for survival are less likely to be attacked and mutated if they are surrounded by sequences of little or no value to survival and good health. Base-sequences essential to life hide within chromatin like proverbial needles in a haystack.
Dolphins have noses but can’t smell; they lack olfactory lobes. Sequences in their DNA have been identified that resemble corrupted versions of sequences related to olfactory lobes in other mammals.
Big chunks of DNA are thought to be junk — relics left behind by billions of years of evolution and change. Junk DNA could be a legacy of screw-ups and obsolescence. Dolphins, for example, have noses, but can’t smell. They seem to have a lot of corrupt DNA sequences related to smell, which are broken and don’t work due to neglect and disuse.
Humans are no different. We have DNA we no longer use. Through disuse, our base sequences, some of them, get corrupted over time, some think, and become unusable. The base sequences don’t get up and go anywhere, though. They just hang around, paralyzed, doing nothing. They become unrecognizable to the RNA elves, who learn somehow to avoid them.
Mitochondria and bacteria don’t seem to have much, if any, junk DNA, but humans, like other animals and plants, have almost no nuclear DNA that isn’t junk. It’s kind of mysterious.
A Russian agronomist from the Soviet era, renown in his time as an expert on the cultivation of wheat, Trofim Denisovich Lysenko, believed that plants and animals which were unlucky enough to find themselves subject to environmental stresses could draw on reserves from a pool of what is today called junk DNA to change their hereditary direction and enhance their survival odds. His idea has yet to be discredited.
The simple onion has 16 billion base pairs in its DNA. The loblolly pine tree — it’s an important source of lumber, which thrives in southern swamps — houses 22 billion. Humans have 3 billion.
EDITORS NOTE:As of January 2018, a Mexican salamander that can regrow limbs (the axolotl) has been sequenced. It is known to have 32 billion base pairs.
What do all these bases code for? They code for nothing, apparently. Maybe they are a warehouse of survival tools left behind as the distant past of billions-of-years ago gradually transforms itself into now; our miraculous present.
Another compelling idea that occurred to me as I wrote this essay is that the tangled mess of unused DNA in every plant and animal might have grown both in volume and complexity during ancient times — quite apart from environmental pressures on the life-forms themselves.
Could massive DNA growth have preceded evolution to enable and accelerate biodiversity during unforeseen environmental catastrophes?
It’s important to find out, because statistical studies on the rate of mutations seem to support the idea that mutational frequency cannot be the primary driver of species differentiation. Mutation rates are too low; the process is a snail’s pace compared to what is needed to transform a chimpanzee for example into an orangutan; or primates of any kind into humans.
Is it possible that mammoth reservoirs of disorganized and unused bases grew and multiplied inside the nuclei of ancient cells — like molds in petri dishes — to fuel bio-explosions of diversity and complexity when conditions were right? It’s a thought.
An abundant supply of unused DNA combined with aggressive colonies of swarming RNA segments might help to explain rapid, diverse bio-blooms (and even account for absences in fossil records) that seem to have occurred during the Cambrian era — to cite one example out of many.
The world’s smartest people are just getting started in the field of molecular genetics. Despite all that others have learned, much remains to know; more, much more, remains to discover and understand. Secrets hide in the complexity that are certain to better explain how biodiversity bloomed on planet Earth.
DNA bases are not a code, it seems to me; they are simply a platform for departing mRNA trains that, when properly coupled, can become assembly templates for chains of amino acids — complex assemblies of molecules that depend on very many processes and structures to have even the remotest chance of being transfigured by ribosomes into a seeming infinity of unlikely proteins — matrices of proteins and other structures, which have risen from the dust and the seas like the miracles of angels; an endless froth of bubbles; a deluge of structures that have over eons shaped the messy, sometimes ugly, often beautiful human beings and all other life on our planet; our home; our beloved Earth.
Adam Rutherford, the British geneticist said, ”This is the definitive history of arguably the greatest of all scientific revolutions.”
Life’s Greatest Secret is a must read for anyone who is interested in the science and history of the human genome. We strongly advise our readers to buy and read this important book. Billy Lee has read it twice, marking it up each time with magic-marker and margin-notes. It is a science blockbuster; a fantastic book written in an engaging, easy-to-understand style.

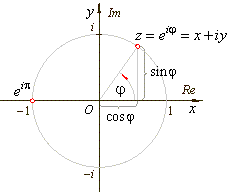
 ?
?
 . The point is shown at .2078… on the real number line. An imaginary number raised to the power of an imaginary number yields a result that is a real number. How can that be? It’s something to ponder; something to think about. The Editorial Board
. The point is shown at .2078… on the real number line. An imaginary number raised to the power of an imaginary number yields a result that is a real number. How can that be? It’s something to ponder; something to think about. The Editorial Board  ?
?  to stretch or shrink the unit circle of values. We aren’t going to go there. In this essay “e” is always preceded by the number “one“, which by convention is never shown.
to stretch or shrink the unit circle of values. We aren’t going to go there. In this essay “e” is always preceded by the number “one“, which by convention is never shown.












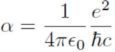

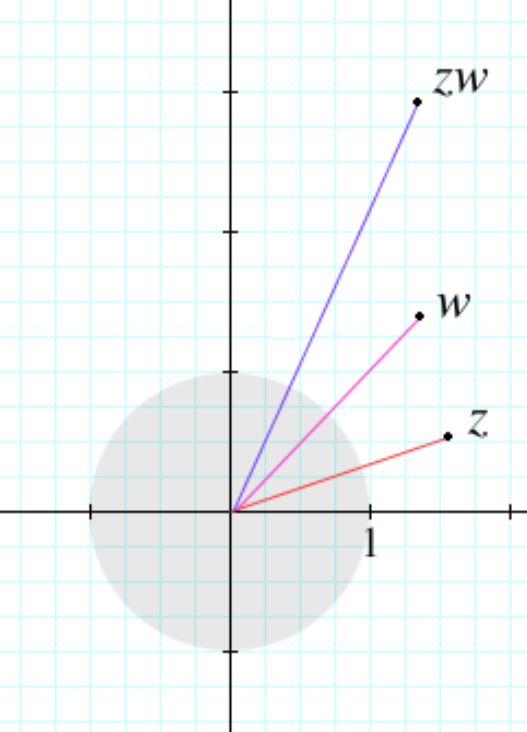

 for gravity;
for gravity; for fine-structure.
for fine-structure.

 =
= 

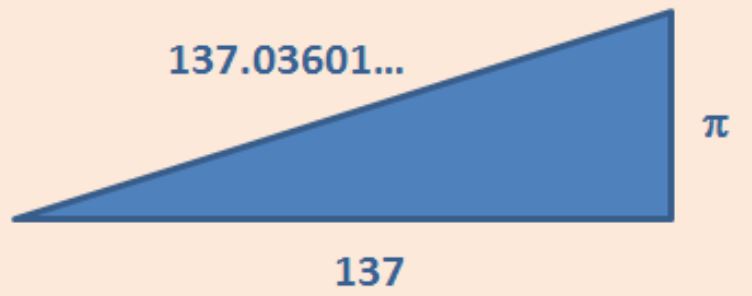
 .
.


 . This strange relationship is another indicator that something fundamental is going on at a very deep level, which no one has yet grasped.
. This strange relationship is another indicator that something fundamental is going on at a very deep level, which no one has yet grasped.